





Key-value databases have long been used for a variety of applications to provide pre-computed results in real-time. There is, however, an increasing shift towards using Graph technology for real-time applications that illustrates how this game-changing approach is not only ideal for complex datasets and complex queries, but also for simple real-time applications. Graph technology reduces memory consumption, improves app latency, simplifies app development and more.
Here is an example use case in personalized e-commerce recommendations. The business precomputes a list of products to be recommended for each end user using various recommendation models. For example here are three possible models:
Model 1 (based on gender and age)

Model 2 (based on each user’s past behavior)

Model 3 (based on other users who have similar purchase patterns)

Key-Value Approach
Each recommended product list for each user is stored as a key-value pair in a key-value database. Key=UserId, Value=List of ProductIds to be recommended. To recommend products to a user, the e-commerce app will retrieve the list of products based on userid. The eCommerce app often retrieves multiple recommended product lists based on multiple models and then selects a few products from each list to provide balanced recommendations to the user according to a scoring formula. How likely a product is to be recommended can be based on a weighted scoring. For example, a 20% weight is given to Model 1, a 50% weight is given to Model 2, and so on. A product appearing in multiple models (with higher weights) will have a higher probability of being recommended to the user.
Key-Value Problems
1) Inefficient organization of data: Each user is duplicated in each model, and each product could be duplicated many times across the database. to find out which users have a recommendation for a given product (a reverse key-value lookup), there is no way to do this except to read the entire database and then process the results.
2) Lack of computational ability and efficiency: Key-value stores are designed to be simple — just store and quickly look up values. The simple computation of a weighted score is beyond their ability; instead an application-level program needs to be written. This leads to transferring unnecessary data (products which won’t be recommended) from the Key-Value DB to the app (end users) and this reduces the app’s responsiveness and user experience.
3) Lack of Semantic Modeling or Partitioning – There is also one big practical issue with storing the key-value pairs (UserID-productId list in our example) for multiple recommendation models: the most popular Key-Value DBs don’t have efficient ‘namespace’ capability. This means there is no built-in capability to separate the one key-value table into different recommendation models. As a consequence, the developers either need to create and use compound keys (in our example, combining UserId with model name) if the developers use only one Key-Value DB instance (increasing memory usage) or they have to deploy multiple Key-Value DB instances, each of which is for one particular recommendation model (increasing programming complexity and cost).
Graph Approach
In a native parallel graph database like TigerGraph, the problems described above are solved intuitively. Figure 1 shows a sample graph schema.
Figure 1. Sample schema for personalized recommended products
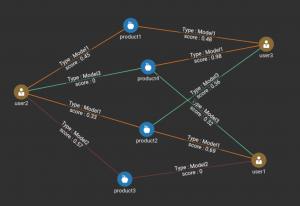
Figure 2. Sample Data Graph
Graph Model
Each user is represented by a single vertex, with a unique UserId key. Each product is also represented by a single unique vertex. An edge connecting a User vertex and a Product vertex means that the product is recommended to the user by the model represented by the edge’s type. In this example, there are three types of edges to represent three models in the example.
Simple Retrieval. It is simple and fast to get a user’s list of recommended products. The graph DB just returns the list of Products connected to the User by the edge type representing the model. Figure 3 shows the GSQL code for this retrieval.
CREATE QUERY getRecByModel(vertex<User> inputUser, string model, int k) FOR GRAPH MyGraph {
Start = {inputUser};
Result = SELECT t FROM Start-(model:e)-:t LIMIT k;
PRINT Result;
}Figure 3. Given a user and a model, return recommended products.
Weighted Scoring. Unlike key-value DBs, graph DBs typically come with a query language with at least of computational ability of SQL. A weighted score is well within their ability. For example, Figure 4 uses the Turing-complete GSQL language to calculate the weighted recommendation score for each product recommended to the given user, sort the scores, and then return just the top k recommendations. Moreover, due to the massively parallel processing (MPP) of the TigerGraph engine, even if there is a huge number of recommendations to consider, the results can be computed in real time. The GSQL query could be easily enhanced to take to take more input parameters, such as the weights of the models, to dynamically update the scoring scheme.
CREATE QUERY getRecAllModel(vertex<User> inputUser, int k) FOR GRAPH MyGraph {
MaxAccum<float> @weight;
Start = {inputUser};
Result = SELECT t FROM Start-(:e)-:t
ACCUM
CASE WHEN e.type == Model1 THEN
t.@weight += e.score * 0.2
CASE WHEN e.type == Model2 THEN
t.@weight += e.score * 0.5
CASE WHEN e.type == MOdel3 THEN
t.@weight += e.score * 0.3
END
ORDER BY t.@weight DESC
LIMIT k;
PRINT Result;
}Figure 4. Given a user, return the top k recommended products based on a weighted scoring of all the models.
Conclusion
This article shows how a graph database can efficiently solve key-value problems by saving memory, reducing query latency and simplifying app development. Graph Database’s capability is of course far more than what is shown here. For example, we can use GraphDB to do real-time product recommendation on live data (such as collaborative filtering) instead of doing offline batch computation on stale data. The power of a native parallel graph database (compression, fast, parallel processing, ease to use SDK) really help enterprises solve a wide range of problems.
There’s never been a better time to get started with TigerGraph and one of the best ways to do that is by scheduling a demo with one of our experts. Alternatively you can test drive or get started with our developer edition.







