





Introduction
User-defined Indexes or Secondary Indexes (as they are commonly called in Database Industry) are a critical feature that enhance the performance of a database system. Indexes allow users to perform fast lookups on non-key columns or attributes without a full-fledged scan. Although this feature is a popular feature for relational databases, it has become essential for Graph databases as well.
Feature Description
Overview
This is a brand new feature that is being introduced in Ver 3.0. This is primarily a performance enhancement for Querying the data. TigerGraph is a native Graph database which provides easy traversal for multiple hop queries via index-free adjacency.
However, even with Index-free adjacency, users still have to deal with large Vertex level data as some vertex types can have lots of attributes. User-defined Indexing allows users to access specific non-key attributes easily and filter the size of data in each Vertex. GSQL language has extended DDL, IUD and Query commands to support User-defined Indexes. The new syntax is based on existing commands to ensure similarity and continuity.
High-level Feature Design
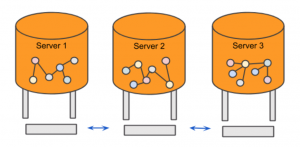
TigerGraph Database allows users flexibility to define User-defined Indexes on Attributes. The following table provides details on supported operations for Indexes:
Architecture Overview
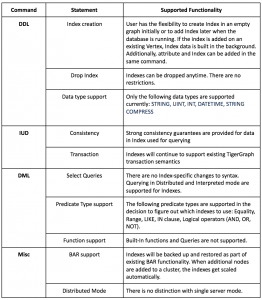
Co-location of Graph Data and Index Data
Just like the base graph data, index data needs to be partitioned as well to scale to very large datasets. Our design is to co-locate the graph data and its corresponding indexes on the same server.
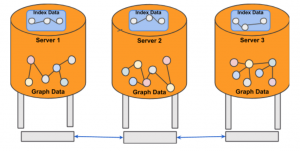
There are many benefits due to this approach:
-Index updates can be done locally together with the graph data in a single local transaction without having to introduce a more expensive distributed transaction.
-By co-locating the index and graph data, the fetching of graph data can be done efficiently on the local server without having to introduce any additional network transfer cost.
-Partitioned index mitigates the issue of skewed index entry, e.g., one index value has a huge number of matching vertices, which can pose a significant performance risk.
Transactional updates on graph and index data
In TigerGraph, all read and update operations on the graph data are backed by transaction protections. This is extended to the index data as well. Queries will see a consistent view of Index data.
Fault tolerance and High Availability
Since the secondary indexes are co-located with graph data locally on our Graph Processing Engine (GPE) server, they can leverage the full fault tolerance / high availability capabilities of TigerGraph’s query engine.
Benchmarking Results
TigerGraph Performance Engineering team conducted performance testing using industry standard TPC-H benchmark for User-defined indexing features. The aim of this exercise is to demonstrate the performance gains of the feature as well as recommend best practices for users with this new feature.
The TPC Benchmark H (TPC-H) is a decision support benchmark. It consists of a suite of business oriented ad-hoc queries and concurrent data modifications. Scale factors used for the test database must be chosen from the set of fixed scale factors. The testing was primarily focused on Index performance testing. Cardinality of distinct values in the attribute was chosen to test the efficacy of using a User-defined index for that attribute. There are three cardinality levels chosen: Low, Medium and High.
Low distinct value cardinality on attribute
This type of query is a simple query on an attribute with a low number of unique values. For example, an attribute like ‘flag’.
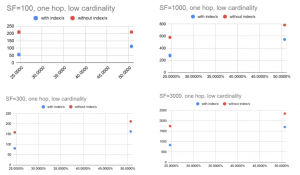
Figure 1 : Low-cardinality Queries
X-axis: Query selectivity with respect to total data size. Y-axis: Query execution time in seconds
As you can see from the results, there is a clear performance gain due to reduced data access. There are performance gains even when 50% of data are being accessed.
Median distinct value cardinality on attribute
This type of query is a simple query with a moderate number of unique values. For example, an attribute like date that can consist of a large number of entries.
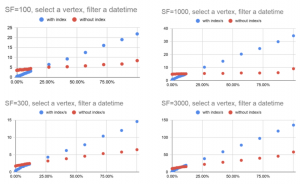
Figure 2 : Medium-cardinality Queries
X-axis: Query selectivity Percentage. Y-axis: Query execution time in seconds
As you can see from the results above, the selectivity of the predicate will determine if Index can help for attributes with Medium cardinality. For example, if the attribute is of ‘Date’ type, one value can have high Query selectivity which can result in large scans of a lot of index entries for this range query. In such a scenario, User-defined will not be of much help when more than 10% of data are being accessed. On the other hand, if the predicate has low selectivity), query with a user-defined index will give substantial performance boost.
High distinct value cardinality on attribute
For the case of high unique values, we observed similar results as Medium cardinality. For example, if the attribute is like an ID which is unique to every vertex, if the selectivity of the predicate is high, it can result in large scans. In such cases, the presence of User-defined Index doesn’t help much with performance.
In conclusion, the best fit for the User-define Index are queries with the following characteristics:
-Low distinct value of the attribute
-Low selectivity query on the attribute
Full official report of the performance benchmark will be published on TigerGraph’s website later.
Conclusion
In this blog, we provided a high level design and architectural overview of user-defined indexing feature. We have also shared an overview of performance benchmarking results. This is a very important feature that will build further on TigerGraph MPP architecture to run the most demanding Graph query workloads.
Get started with TigerGraph Cloud free here: www.tigergraph.com/cloud







