





by Chinmay Nerurkar originally posted on Medium
One of the main drivers of the AT&T, WarnerMedia and Xandr success story is the synergy derived from combining our data assets. This combination supports solutions for customers including our cross-device products, targeting the right users, and content personalization. The amount of data housed by these companies is not only large, containing billions of identifiers, but it also consists of various types of identifiers (e.g., user accounts and cookies). Additionally, information from other third-party data providers is used to further extend our data coverage and provide a wider breadth of offerings to our clients. To support all the advantages described above, Xandr has consolidated data from these different sources using TigerGraph to build a connected Identity Graph.
What is an Identity Graph?
An Identity Graph Database stitches together different identifiers from disparate datasets into a unified view of people, the households they belong to, and the devices they use.
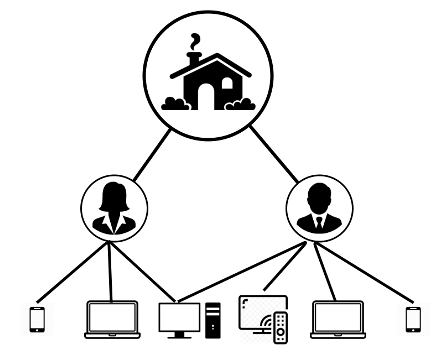
Each individual may have personal and work phones, laptops they use for work, browsing and social media activity, a connected TV in their living room to stream their favorite shows or play games or all of the above. Connecting ad identifiers for all these devices together enables Xandr to provide its cross-device products and converged addressable offerings. The identity graph helps to perform frequency-capping at the household or user level which in turn ensures efficient advertiser spend. Furthermore, advertisers can find more consumers with Audience Extension and increase their campaigns lift with conversion attribution across different devices.
Finally, consumers demand that the ads served to them be relevant and personalized but also that their privacy be respected. Xandr’s identity resolution solution helps us manage consent elections across first party assets and third party data.
What does the Identity Graph look like?
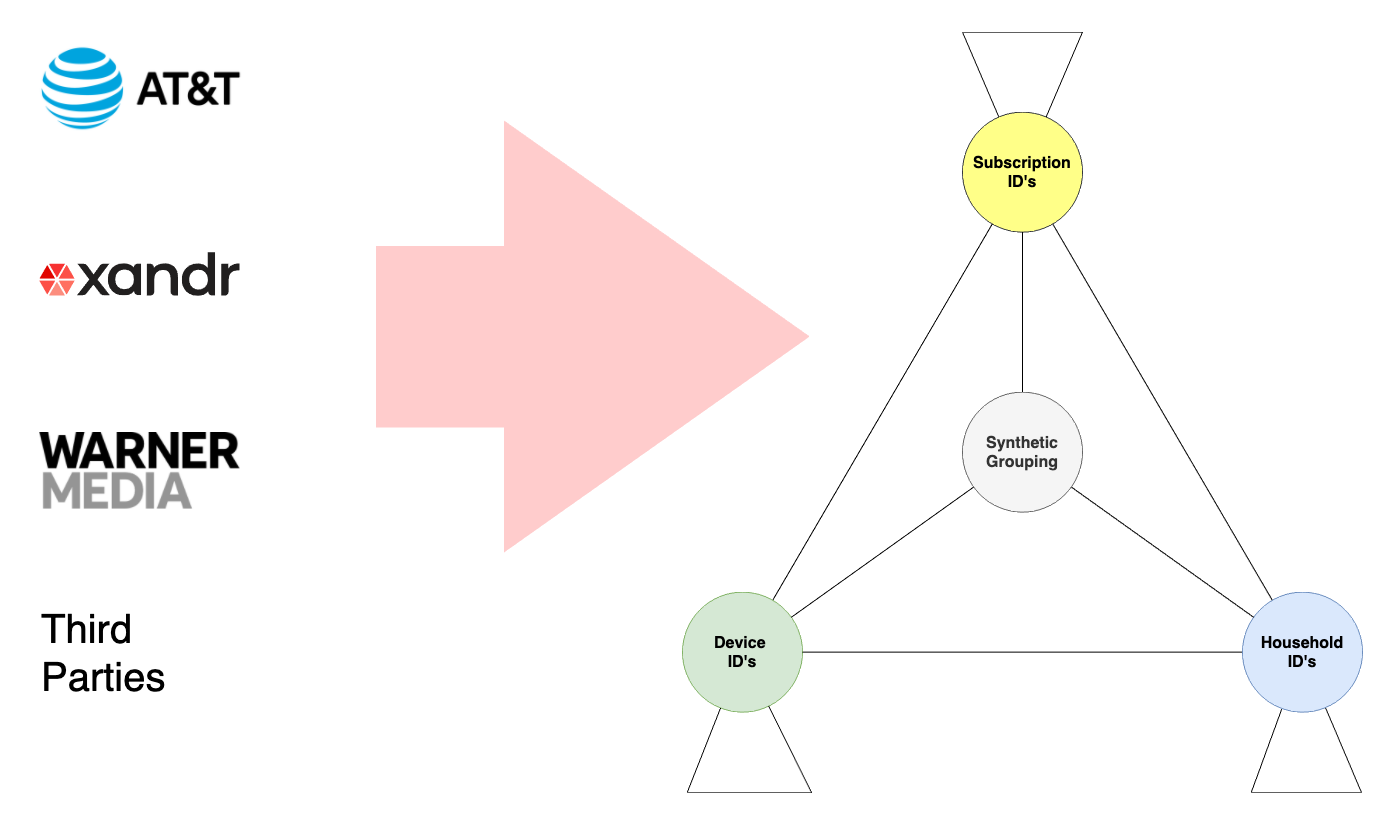
The graph model is comprised of vertices that represent certain types of identifiers (e.g. cookies, devices, households, etc.) connected by edges that represent the underlying relationship between them.
The Xandr Graph is built based on “identity” data from multiple sources including AT&T product and services, Xandr online advertising traffic, and third party data suppliers. Each data file from a particular source will contain rows of related ad identifiers. The identifiers on each row are mapped to a vertices in the graph and connected by edges. In most cases, at least one identifier on a row of identifiers from a given source will be present on a row of identifiers coming from another source. Using the common identifier, these two rows can be stitched together into a single grouping of related vertices connected by edges. Some source files also contain additional metadata that is stored as a property of an associated vertex. To produce our identity graph solution, we use TigerGraph, a distributed native graph database, that makes understanding and mutating relationships more intuitive and easier to model than a traditional database utilizing countless table joins.
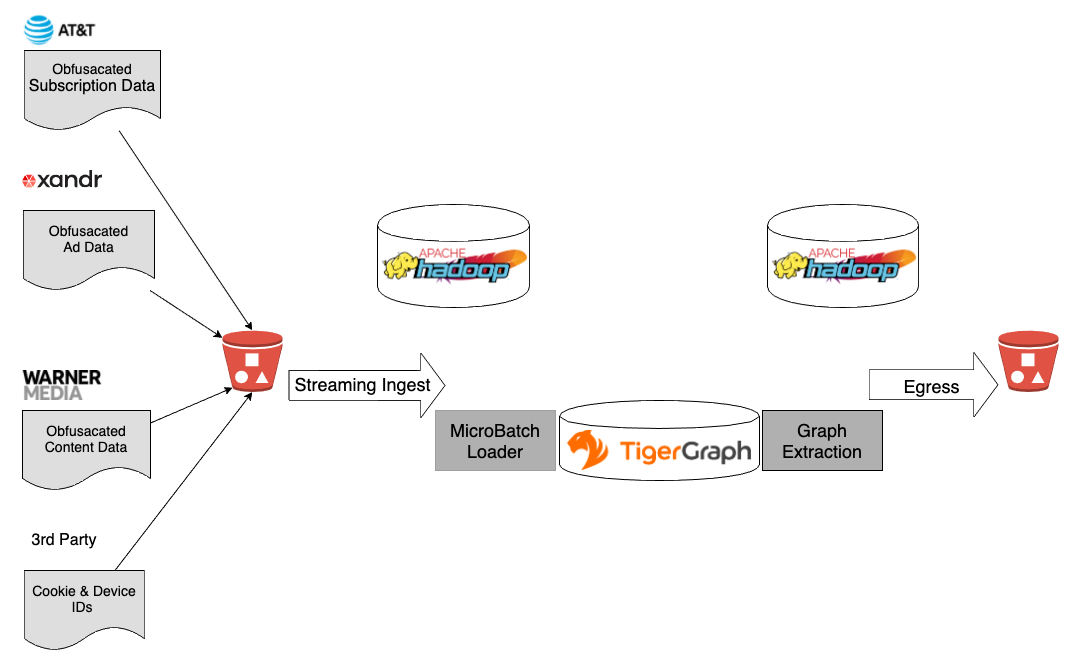
TigerGraph sits in the middle of the Xandr identity platform architecture, between the ingress and egress systems. These systems support both streaming and batch processing of data. The platform uses Hadoop and Apache Spark for cleaning, filtering, and aggregation before loading the data into the graph and for application of the post-processing rules on the output of the graph. We use TigerGraph to curate relationships in our identity pool and run graph processing algorithms like our Identity Resolution on the graph.
Graph-based Identity Resolution
Since our identifiers are represented by vertices and relationships between them by edges, we start our identity resolution by running a label propagation algorithm. The label propagation helps us find all connected components of identifiers (i.e., Is there a path between any two vertices?). We considered several candidates for the label propagation algorithm and selected HashMin because of its low memory requirements.
TigerGraph provides a handy unique numerical internal ID for each vertex in the database regardless of vertex type or content. When implementing HashMin, we first assign a label to each vertex equal to the TigerGraph internal ID and then update each vertex’s label to the smallest label value across all its neighbors. This update process is repeated until all the vertices in the connected component have the same unique label.
Between successive runs of the label propagation algorithm, we may load new data into the graph, run TTL jobs to expire some vertices and edges, delete some vertices that have been identified as bad data, etc. This can change identity groupings. For example, some of the connected components can lose an identifier and split into two or, conversely, gain a connecting identifier merging two smaller connected components into a larger one. As a result, when re-running HashMin similar or the same identity groupings may receive different labels. This makes it hard to keep track of identity groupings consistently across multiple runs of HashMin, which is not ideal for Ad-serving. In order to achieve label persistence between different runs, we use a modified version of the Gale-Shapley algorithm. This algorithm ranks and matches connected components between two consecutive runs. As a result, we can overwrite the newer label with the older label for the matched pair of connected components.
We also sometimes see very large connected components that join multiple synthetic groupings (ones which we want to preserve) with edges as the result of running label propagation. To break them down, we use centrality measures.
How does this run?
The Xandr Identity graph is comprised of more than 5 billion vertices and 7 billion edges. We apply over a billion updates to the graph every day. Running identity resolution also generates hundreds of million new vertices and edges. To accommodate these data volumes and processing demands, we built a 10 node TigerGraph cluster. Each cluster node has 48 cores, 400 GB RAM and fast 3 GBps NVMe storage.
New data is loaded into the cluster at the beginning of each day. This could be a full data refresh for a particular source or an incremental update. We built a data ingestion pipeline to receive input from different sources, normalize and clean it, and then translate it to JSON format and load it into TigerGraph over RESTPP API.
After the data load is complete, we run a series of GSQL queries (i.e., Label Propagation, breaking down large connected components and Label Persistence) to perform Identity Resolution. An in-house data platform job scheduling system kicks off GSQL queries on a set schedule and manages their life cycle. It also ensures that all the queries are successfully executed in serial order. When the identity resolution queries complete successfully, another job runs a GSQL query to extract synthetic groupings from TigerGraph and generates the graph output. We have an egress pipeline that applies consent and privacy rules to the graph output and sends it to the client’s Amazon S3 buckets. This cycle of ingesting new data, applying graph processing and delivering updated synthetic groupings to the clients repeats automatically at a regular cadence.
But, does it scale?
Working with a highly connected graph at our scale comes with its unique set of challenges. Our graph is large in size and distributed across multiple TigerGraph nodes. Running graph algorithms that perform breadth-first traversal of large graphs is extremely memory intensive on a per cluster node basis. This is due to the necessity to load all the connected components that are related to each other into the RAM of a single machine. As the graph grows in size and connectedness, the graph queries have a higher likelihood of running out of memory and aborting. Adding more RAM to clusters could help to an extent, but ideally we want our graph algorithms to scale horizontally.
An elegant solution for our scale problem is a divide and conquer approach to the graph processing. Running your queries on the entire graph can fail to scale as the graph grows due to the reasons stated above. We instead split the graph into smaller mutually exclusive sub-graphs (shards), then apply our identity resolution algorithms to each shard independently to generate a solution for the shard. The number of shards is picked based on the memory requirements of the graph query. This means that, as our graph grows and is enhanced with more insightful connections, we can continue to scale Identity Resolution by splitting the graph into more shards. We also built a data pre-processing pipeline to filter out potentially bad actors in the input data that could interfere with the stability of our graph algorithms before being loaded into TigerGraph. This approach allows us to significantly reduce memory utilization per cluster node and increase the operational stability of Identity Resolution on the TigerGraph cluster.
Lessons Learned

The Xandr Engineering and Data Science teams worked closely with TigerGraph engineers on this project. We learned a lot through this collaboration project. I am sharing a couple of important lessons below.
Lesson #1: Employ Graph Thinking when solving Graph problems
Non-native graph databases store data in tabular format and generate indices on certain key columns. Database queries rely on these indices to implement where clauses and join operations. A native graph database like TigerGraph uses native graph storage to store related vertices and the connecting edges together. This enables fast traversal of related vertices using pointer-jumping and allows us to perform complex join operations without the need for indices. Be sure to make use of this Index-free adjacency feature when designing graph queries to problems involving multiple complex joins.
Lesson #2: Solve large-scale graph problems in a MapReduce fashion
TigerGraph is built to store and process large graphs in a distributed fashion across multiple cluster nodes. Queries that solve a problem by applying complex logic across the whole graph can be extremely memory intensive and may not succeed. Instead, restructure your query logic to solve sub-problems on smaller parts of the graph and then combine the sub-solutions to get the final result. This approach enables faster processing on larger graphs using the same hardware.
Lesson #3: Configure the graph database for your use-case
TigerGraph itself is extremely configurable and lets you tweak how the graph is stored and processed. Whether you want fast query times or intend to run complex graph processing algorithms, configuring the cluster to match your use-case will make all the difference.
This work was presented at Graph+AI World 2020 by Yana Volkovich, Subha Narasimhan, Michael Berry, and Chinmay Nerurkar







