





Paradigm Shift Enables TigerGraph to Uncover Hidden Insights from Geolocation Data
Have you wondered how you can add and leverage geospatial data to your applications? There is a massive amount of value untapped in this space. In 2017, the geospatial analytics market reached $38.65 billion. It is estimated to grow at an annual rate of 18.2%, and by 2027, the entire geoanalytics market will reach $174.65 billion. The large return on investment (ROI) associated with adding geospatial insights to your business has sparked the interest of 78% of C-level executives who are now considering investing in location data. As a startup founder, or a product owner at your company, geo-related data initiatives should be a no-brainer. To understand the scale of the market, check out the TigerGraph geospatial solutions page.
Some of my observations about the big data industry:
- We collect data, but we don’t fully use the data.
- The traditional solutions find it too difficult to integrate the collected data, so we pipe it into a data lake, put it to sleep, to waste away.
Recently, my mindset towards the geospatial analytics field has changed. Coming from the relational world, then navigating through document DBMS and multi-modal DBMS, I experienced a paradigm shift when I arrived at TigerGraph, particularly pertaining to how we leverage location data. In the past, you may not have considered location data because the implementation requires additional geospatial software to handle the analytical workload, or a third party index in addition to your DBMS engine. A graph database, on the other hand, naturally models an unbounded number of dimensions, including organization hierarchy, time dimension, and location/geospatial hierarchy. In particular, I realized that TigerGraph’s real-time deep link analytics opens up the solution space and uncovers the hidden insights from collected location data.
Design For Future
The pain points have always been around the inflexible schema and architecture in traditional data management systems. You may need to rethink your architecture all the way to design for now and the future. There is no exception when we brainstorm about geospatial applications.
From the technology side, a modern platform like TigerGraph allows us to design for the future with flexible architecture and a performant engine. Geospatial analytics is essential to fulfill the potential of the Internet of Things, Artificial Intelligence, Autonomous Driving and Edge Computing. These applications will require TigerGraph’s real-time deep link analytics from geospatial data. As a hybrid OLAP and OLTP graph database engine, TigerGraph is a future-proofing technology choice. I am excited to see more geo-enriched applications in the future based on TigerGraph.
Technical Approach
In our Graph Guru 8 webinar, we give you a detailed look at our GeoGraph reference design for a geospatial search application based on TigerGraph. Here’s a quick preview of GeoGraph:
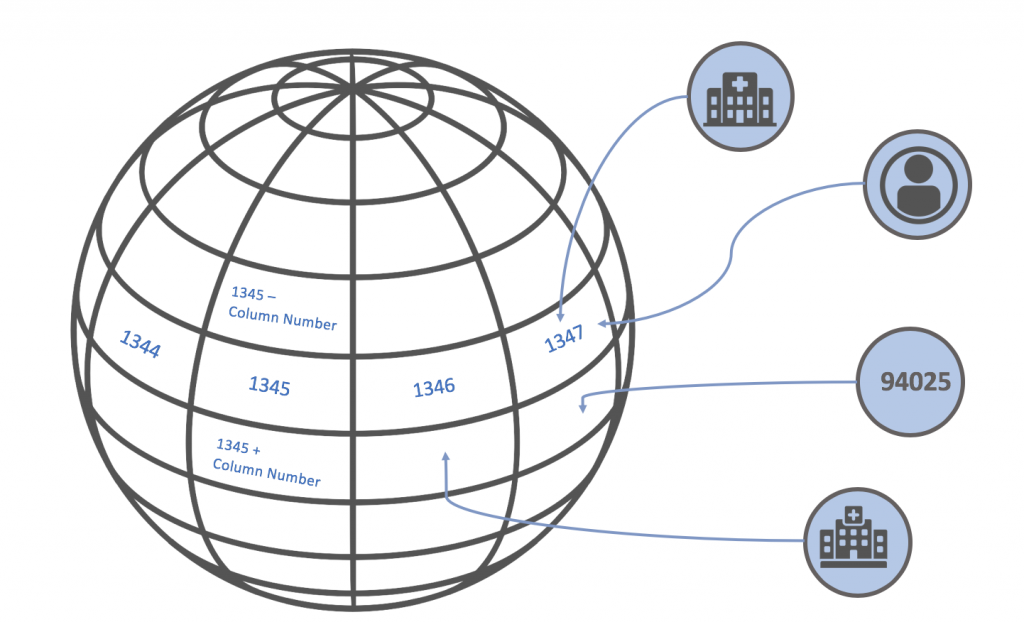
- Partition the earth into a grid of bounding boxes or cells. Boxes that follow latitude and longitude lines are the most straightforward.
- Represent each box by a vertex in the graph.
- Assign each grid box an ID, which is x + y*c, where (x,y) is its location in the grid, and c is the number of columns.
- For each Object vertex having geolocation data, create an edge between the Object vertex and the grid vertex corresponding to its geolocation..
Visually, each grid cell or each object is represented as a vertex, and it is connected to nearby object vertices with location edges. See the following diagram for details. “Object” here can be people, things, vehicles, sensors, or anything else with a geolocation.
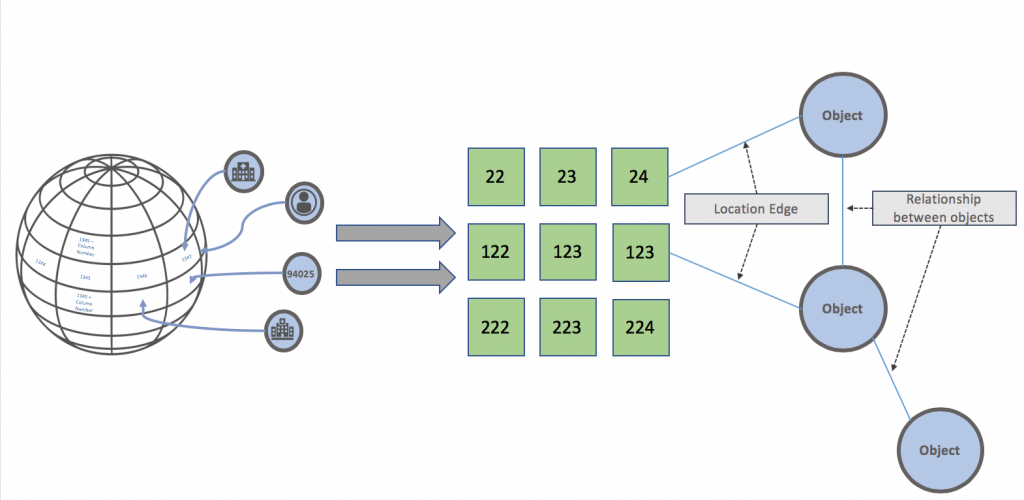
Then, when searching for objects close to a given Object or location, we can use the GeoGraph to instantly find the set of Objects that are within the same geocell, as well as those in neighboring cells.
The current implementation is very lightweight and elegant, which demonstrates the versatile nature of the TigerGraph engine. I encourage readers to follow our solution engineer Xinyu Chang’s instructions to design the graph schema, map the data, write the GSQL queries to recreate the application (see instructions via github).
Next Steps
To learn more about how TigerGraph can leverage your geospatial data:
- Visit our new solutions page on Geospatial Analysis.
- Listen to our Graph Gurus episode on Geospatial Analysis with a Native Parallel Graph Database.
- Experiment with the dataset from our Graph Gurus webinar using TigerGraph’s Developer Edition and build a proof-of-concept Geospatial Search application.
Also stay tuned for Part 2 of this blog topic: Implementing GeoGraph on a Native Parallel Graph Database.







