





This is an abbreviated and edited version of a presentation by Dan McCreary, Distinguished Engineer – Advanced Technology Collaborative at Optum, a division of UnitedHealth Group, during the Graph + AI Summit Fall 2021 conference.

Watch the full session from Graph + AI Summit Fall
Today we’ll talk about the intersection of learning, knowledge and language, and where innovation is going to be occurring in Enterprise Knowledge Graphs.
I’m a Distinguished Engineer in a group at Optum called the Advanced Technology Collaborative, which matches emerging technology with the business problems within our business units. For context, Optum employs almost 35,000 IT employees, of which 3,200 are data scientists. We’re not just focused on one domain, such as graph, and not just machine learning, but we’re looking at where these domains come together. And that’s where innovation is occurring.
There are a lot of new ideas that might explain how you can use Enterprise Knowledge Graph (EKG) strategies. So today, we’ll explore more than graphs and TigerGraph — we’ll explore how learning, specifically machine learning, as well as symbolic learning, are going to combine with knowledge graphs symbiotically.
Large language models such as GPT-3, or these Bert models, are in fact, knowledge graphs, and there’s a huge amount of innovation in these. Using them effectively is important because, in healthcare, at least 80% to 90% of our knowledge is tied up not in tables and columns of relational databases, but it’s tied up in documents and clinical notes, and in conversations. Every time that we record a conversation and transcribe it, we have knowledge in those transcripts. We can use that knowledge to find insight into the organization.
We’re also going to talk about the relationship between knowledge graphs and the field of thinking called Systems Thinking. We’re going to apply a way of looking at the world, a type of analysis — Systems Thinking — to our challenge of EKGs, and how to set them up, how to manage them, how to grow them, and how to think strategically about how EKGs fit into the mission of our companies and how we serve our customers.
What Are Enterprise Knowledge Graphs?
At Optum, we think that EKGs are very different from some of the other definitions out there. For this discussion, we see “enterprise” as scaling to multiple departments and growing without having to be re-architected. Think thousands of concurrent users and hundreds of applications, allowing anybody to do ad hoc queries but only see the data they should see given the roles they have. I’m talking about high availability, things like rolling upgrades, detailed high As security, fine-grained control, resource quotas, and a very large library of graph algorithms.
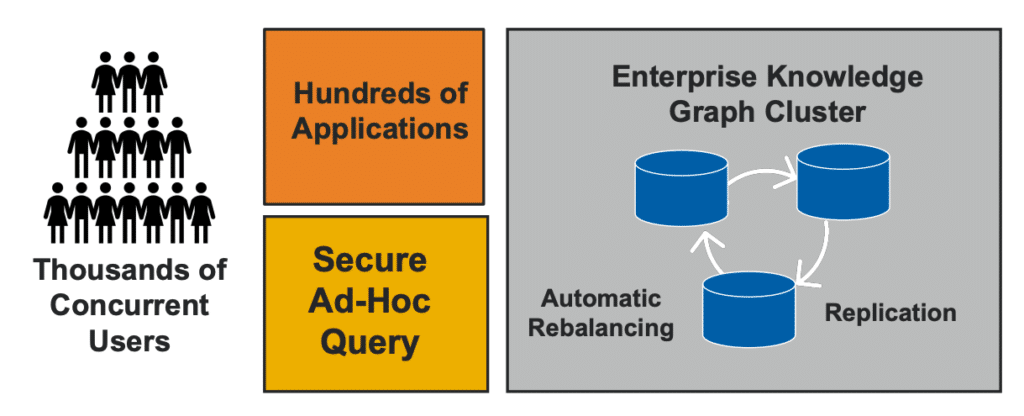
In terms of scale-out, there are several dimensions:
- Scaling out data sizes. Add more data to our knowledge graph without shutting down the servers
- Scale-out compute. Add more compute resources, more nodes, the clusters
- Scale-out security. Allow security to be managed, and continually monitor data quality
- Scale-out algorithms. Add more algorithms without slowing down the server
- Square out query. Add more and more concurrent queries as the system grows.
At Optum, we’ve been working hard to build scalable knowledge graphs about health care because we have:
- 10s of billions of edges in our system and billions of vertices
- 10s of millions of updates every day
- 25,000+ concurrent users.
We have streaming interfaces so that a change reflected in an operational source system is also reflected in our customer service center screens that use the knowledge graph. This happens within 60 seconds, while our users, all of them, have 100 millisecond response times to see a full member journey of all of our customers’ use. Most importantly, we are now starting to see deep insights about clinical value over all of these systems.
We can’t just look at one dimension of our members. We can’t just look at the times they visited our website, their emails, or their claims. We have to pull all of these things together in one place, including their net promoter score. How do all the different things that we’re working on impact their net promoter score, how is their experience with their call centers, or how they pick their plans? All of these things are tied together, and we can’t look at one little dimension at a time. Everything has to be together so we can do cross-domain queries.
Our goal is to get the right information to the right people at the right time. It’s evolving into what we call the central nervous system of our organization, where we have intelligent triggers and proactive alerts so that all of our consumers and healthcare information care coordinators or physicians or nurses, every one of our agents, everybody that’s working in assisted living centers, all of them can get the right notification of the right information. And it’s not just clinical history, it’s also through the Internet of Things, biometric readings that are happening in real-time in our hospitals and clinics. All of those things should be able to notify people, and just the right people, at the right time.
What Is a System?
A system is, in our definition, a collection of components that interact together to produce some sort of behavior. A sample EKG system is broken down into sub-components:
- Source systems that we gather data from
- Change data capture events, every time there’s an insert or update or delete the streams, that we publish those events on
- The graph database that we ingest the data into
- All the many UI systems that we build (for dashboards and reports, and analysis and event recording).
Plus, metadata is really a key piece of that so we can track the lineage of where our data has come from.
What’s important about this is that these systems are inherently complex. They have lots of subsystems, and those subsystems evolve over time. As systems get larger, towards the 10 billion vertex mark, we start to see what we call emergent behavior, behavior that we couldn’t actually predict. But that starts to happen as we put together more complex systems.
Systems Thinking and Examples of its Archetypes
Systems thinking is an approach where we take a holistic look at these components, not one piece at a time, not silo by silo by silo. We’re trying to focus on all the parts and how they relate, and how they interact over time within the context of larger systems.
Artificial Intelligence Fly Wheel
A good example of systems thinking for knowledge graphs is what we call the AI Fly Wheel, one of our archetypal patterns. As we have data in our graph, we can use that data to build machine learning models. Those machine learning models might do things like making predictions of what products a customer might want. How do we gather the feedback about what predictions people like? Why don’t we take that feedback, and add it to our data set to get more data?
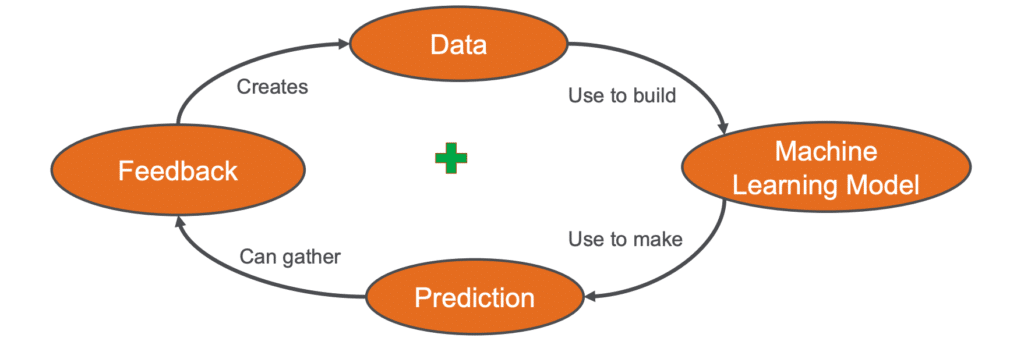
Initially, our predictions may not be very good. As we add more feedback, we get more data, we get better machine models, we make better predictions, and we get a positive feedback cycle. And that’s why we have the plus in a lot of the center of our causal loop diagrams.
Tragedy of the Commons
Another example of an archetype is what we call the Tragedy of the Commons, a story about how farmers in our old medieval villages often had their own pastures, and there was a common area, and they had a rotation system so that each farmer could use it. If the farmers overgraze those common areas, they would become barren, and nobody could use them. So whenever there’s a common resource, we consider how to share that resource so it’s not abused. If there are too many people hitting the knowledge graph at the same time, performance may be slow. So how do we deal with shared resources?
Metcalfe’s Law or the Network Effect
Another archetype example is Metcalfe’s Law or the Network Effect. This is the value of standards and our knowledge graphs. If we have a fax machine, but none of our partners has a fax machine, the value of the fax is very little because we can’t send information to our suppliers or customers. If, however, we have a standard way of representing data, a way to move things in and out of the data that everybody understands, and we manage quality, then that network effect becomes a positive reinforcement, and is valuable.
So, standards are really important, and one of the archetypes that we use when deciding what data we should put into our knowledge graph, and how to standardize or normalize, or canonicalize that data for consistency, so that everybody can share their queries over this data. Architects need to understand how to use these Systems Thinking patterns to help expand and grow the usage of these knowledge graphs.
Systems Thinking is actually a relatively small number of about a dozen core concepts — causal loop diagrams, feedback, understanding positive and negative reinforcement, etc. The trick is, how do we apply this and find archetypes that are appropriate for our internal knowledge graphs, and when to apply them.
Spring 2022 Graph + AI Summit
The Spring 2022 Graph + AI Summit is just over a month away, and registration is open. Don’t miss out on the industry’s only open conference dedicated to democratizing and accelerating analytics, AI, and machine learning with graph algorithms. Register for free today!







