







 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Comcast Corp. is working on ways to better understand its customers’ families. The company plans to roll out features that enable parents to manage the devices their children use at a fine level of granularity. For example, account holders will be able to pause internet access at dinner time or know precisely when their kids are online, said Mark Hashimoto, director of engineering for the “internet of things” in Comcast’s Silicon Valley Innovation Center.
But creating profiles that combine that level of detailed information with the flexibility to accommodate constant change isn’t simple. “If you want to put parental controls on what your children can do with their iPads, we first have to know that you have children, and then which iPad belongs to which child,” Hashimoto said. If multiple account holders are involved, things get even trickier. “Maybe the wife wants notifications in Spanish and the husband wants them in English. We also can’t predict what the customer will want in two years.”
Comcast evaluated a variety of relational, NoSQL and graph databases, looking for one that could closely mimic the relationships that people have and how they view the world. “When we saw what we could do with graph, there was no looking back,” he said. Comcast chose Neo4j Inc.’s namesake graph database as its profile engine. “We found it to be an intuitive way to model relationships among people,” Hashimoto said.
Graph databases are suddenly hot. Amazon Web Services Inc.’s announcement this week of Neptune, a graph database in the cloud, is the latest in a series of recent indications that this once-niche technology is edging toward the mainstream of enterprise information technology.
In September, startup TigerGraph Inc. released a high-speed native parallel graph database platform after raising $31 million in a series A funding round. At about the same time, enterprise software vendor Callidus Software Inc. acquired OrientDB Ltd., creator of an open-source NoSQL database that supports graph and other models. In October, Neo4j overhauled its flagship product with features aimed at making graphs more accessible to business users. And early this year, Microsoft released the fruits of a four-year-long graph database development project to open source.
Graph databases are finding favor for their unique ability to represent complex relationships that rapidly navigate between elements in the database to discover correlations. Forrester Research Inc. analyst Noel Yuhanna said they’re perfect for answering questions like “How many school friends who are not yet connected to me live in Europe and are already connected to five of my closest friends?” or “Is there a dentist in my area whom at least one of my friends visits?”

Neo4j Inc.’s Jim Webber (Source: Neo4j)
Answering those questions with relational tables requires performing multiple joins, each of which consumes more memory as intermediate joins are created. “As you get four, five, six hops into the query, the sets become far too large” and performance tanks, said Jim Webber, chief scientist at Neo4j Inc., whose seven-year-old product is considered the current market leader.
For applications with large amounts of uniform data and densely populated tables, relational databases perform well and are thoroughly understood, he said. However, “Most of the applications I’ve come across could have been better done in a graph.”
Graph databases are still finding their way in an IT world that’s trained to think in terms of rows and columns. Estimates of the market size are hard to come by because the market is still so small despite all the interest. Graph engine developer Bitnine Co. Ltd. estimated that graph comprises about 3 percent of the overall NoSQL market, which Allied Market Research expects to reach $4.2 billion in 2020. That would translate into less than a $100 million market today.
Graph engines require a different approach to application development, a custom storage model and special query tools. They are so specialized that they may not even command their own category for the long term. Eliot Horowitz, co-founder and chief technology officer of MongoDB Inc., believes graph functions will eventually be subsumed into other databases. “I think graph databases are a feature,” he said.
The foundation of graph databases actually predates the relational model. Early enterprise stalwarts such as IBM’s IMS employed hierarchical structures called B-trees that mimicked the navigational schemes of today’s graph technology. But the technology has come a long way, and with endorsements from the likes of Oracle Corp., Microsoft, Teradata Corp. and now Amazon, they may be set to break out.
“We expect the graph database market to grow significantly as organizations look to new approaches in dealing with silos of data,” Yuhanna wrote in a recent report on the market. He noted that a recent Forrester survey found that just over half of global data and analytics technology decision-makers are implementing or already using one or more of the dozen graph options on the market. Graph databases provide “insights and intelligence that were extremely challenging to produce with traditional technologies,” he wrote.
Graph databases have nothing to do with graphics. The reference is to an abstract data type with multiple nodes that can be connected in many ways. Graph structures aren’t relational but aren’t really true NoSQL, either, which makes them a bit of an outlier in the database market. They excel at representing relationships and enabling analysis of complex connections that would tie conventional relational engines in knots.
Graph databases use nodes, relationships and key-value pairs, the latter of which define linked data items using a unique identifier. In graph lingo, these are called nodes, edges and properties. Creating nodes and edges is relatively simple, which is why the technology is useful in discovering and analyzing relationships, as well as creating new ones.
“When you’re traversing the data, you don’t have to do joins across files. Everything is right there,” said Jonathan Lacefield, director of customer experience and graph solutions at DataStax Inc., which acquired the developer of the open-source Titan graph engine in 2015 and rebuilt it as DSE Graph. “The traversals are quick, and there are memory options to store data along the way.”
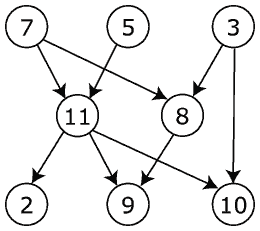
Image: Wikipedia
There are two basic kinds of graph databases. Property graphs represent connected data by mapping nodes and relationships between them, with the ability to traverse the model in any direction (see image below). They’re designed primarily for querying of complex relationships. DataStax and Neo4j both use the property graph model.
RDF triple store is a model developed to support the semantic web. It uses unique resource indicators and a subject-predicate-object metaphor to point to structureless data types in a format that resembles simple sentences, such as “Bob is 35.” This approach is well-suited to web search and navigation. Franz Inc.’s AllegroGraph and Oracle’s RDF Semantic Graph are examples.
The ease of mapping and analyzing relationships is what makes graph databases ideal in areas such as customer recommendation engines and fraud detection. Both applications require that patterns be discovered, such as shoppers who bought ski boots also purchased mittens or buyers who spend below certain thresholds who also may be fraudsters. Both demand that those discoveries be served up lightning-fast in order to deliver an immediate recommendation or accept or decline a credit card transaction on the spot. Social networks also use graph engines to understand relationships among members and identify new connections or affinity groups.
Graph engine scale well and excel at managing complexity. That’s why the International Consortium of Investigative Journalists adopted the technology to power through more than 13 million documents and reveal the multilayered schemes wealthy people and companies use to stash money in offshore tax havens. “I don’t know how we could have done a project this large without the technology,” said reporter Spencer Woodman.
Neo4j’s Webber spent years building applications on relational platforms before the graph epiphany hit him while building a product recommendation system for a manufacturing company. “In the relational world it would have taken four years to do,” he said. “I found a Neo4j catalog and got the application running in a day. I couldn’t believe I had done the project right because it was so fast.”
Whereas relational databases require careful attention to schema design in order to optimize performance, graph databases handle new data elements with relative ease, said Comcast’s Hashimoto. “Edges are very cheap to make in a graph versus doing elaborate joins,” he said. “Graph is more or less schemaless. If we need to create a new element like an account or a preference, it has the flexibility to do that.”
DataStax’s Lacefield sees demand growing as organizations increasingly pursue individualized experiences based upon more holistic understanding of customer relationships. “It’s about taking all the ways a customer is connected to a business and tying them together,” he said.
For example, understanding that two bank account holders are married and part of the same household “is incredibly difficult to do in the relational world because records have been tied to a single customer. Tying in mobile relationships is even more difficult.” But in a graph edge, creating nodes and connecting them with key-value pairs is trivial.
DataStax has been selling its graph engine for about a year and the customer base has doubled from 20 to about 40. “I think in the future this is going to be a core technology for DataStax,” Lacefield said.
However, overall market awareness is still low and many customers are unsure they want to make a large commitment to a niche technology. Graph technology requires its own storage model and doesn’t work directly on relational tables. Graph databases also use custom query languages that differ from standard SQL syntax.
Advocates say resistance to change is the biggest factor holding back graph’s ascension. “When you get out of relational, referential integrity and a locked environment, it’s a learning curve,” Lacefield said. “How you build the application is different.”
Old habits die hard and customers are comfortable with relational technology, said Neo4j’s Webber. “The biggest challenge is education; there is another way, but it means learning something new,” he said. “If all I’ve got is a hammer, then every problem is a nail. Relational is a beautiful hammer.”
THANK YOU





