

First in our series of blogs straight from our engineers to you.
In today’s digitally interconnected world the proliferation of data has presented both unprecedented opportunities and challenges. One of these challenges is the need to accurately identify and link entities across various datasets, a process known as entity resolution. Enter TigerGraph – a native parallel graph database and analytics platform revolutionizing the field of entity resolution. This blog post explores the benefits of utilizing TigerGraph for entity resolution, both in batch and real-time scenarios, and highlights its role in fortifying fraud detection mechanisms, particularly in combating identity fraud.
TigerGraph’s unique architecture based on graph database technology offers several advantages that make an ideal choice for handling entity resolution tasks:
- Flexible Data Model: TigerGraph’s native graph model allows for intuitive representation of complex relationships and hierarchies between entities. This flexibility is crucial for accurately identifying and linking entities across disparate data sources.
- Efficient Parallel Processing: TigerGraph’s native parallel processing capabilities enable rapid data ingestion, processing, and querying. This is crucial for both batch processing and real-time scenarios where quick decision-making is paramount.
- Scalability: TigerGraph’s distributed nature ensures seamless scalability as data volumes grow. This scalability is essential for accommodating ever-expanding datasets and maintaining high-resolution accuracy.
- Advanced Algorithms: TigerGraph provides a rich library of graph algorithms that can be seamlessly integrated into entity resolution workflows. These algorithms help uncover hidden connections and similarities between entities, enhancing the accuracy of the resolution process.

Benefits of TigerGraph for Entity Resolution
- Accurate Linkage: TigerGraph’s ability to capture intricate relationships between entities leads to more accurate linkage, reducing false positives and negatives in the entity resolution process.
- Real-time Insights: In scenarios where real-time identification is critical, TigerGraph’s low-latency query performance ensures timely insights, enabling proactive fraud detection and prevention.
- Holistic View: TigerGraph’s graph-based approach allows for a holistic view of entities by capturing not just direct relationships but also indirect associations. This helps in identifying complex patterns of fraud that might be missed using traditional methods.
TigerGraph and Identity Fraud Prevention
Identity fraud is a pervasive and rapidly evolving form of fraud that can have far-reaching consequences for individuals and organizations. TigerGraph plays a pivotal role in safeguarding against identity fraud through its entity resolution capabilities:
- Pattern Detection: TigerGraph’s graph algorithms can identify suspicious patterns that indicate potential identity fraud, such as multiple accounts linked to a single entity or unusual cross-network interactions.
- Behavior Analysis: By tracking and analyzing the behavior of entities over time, TigerGraph can detect anomalies and deviations from established patterns, flagging potential identity fraud attempts
- Watchlist Matching: TigerGraph can efficiently match entities against watchlists and historical data to identify known fraudulent actors, helping prevent their unauthorized access or transactions.
- Collaborative Intelligence: TigerGraph can facilitate collaboration between different departments or organizations by providing a unified platform for sharing and analyzing entity data. This enhances the collective ability to combat identity fraud on a larger scale.
Example
The following is an example based on a real use.
Schema
In the below schema Entity Resolution is being performed on the Customer entity using 10 PII attributes (First_Name, Last_Name, Gender, Address, City, Country, Postal_Code, Phone, Email, and Date_of_Birth). The 3 _Hash vertices are used to store minHash values for respective Address, Phone, and Email fuzzy matching. All queries support weighted PII attribute(s) and threshold that can be statically or dynamically set per request. The entity can be any data vertex and PII attribute(s) can be any 1-hop neighbor vertex(ices) from the entity.
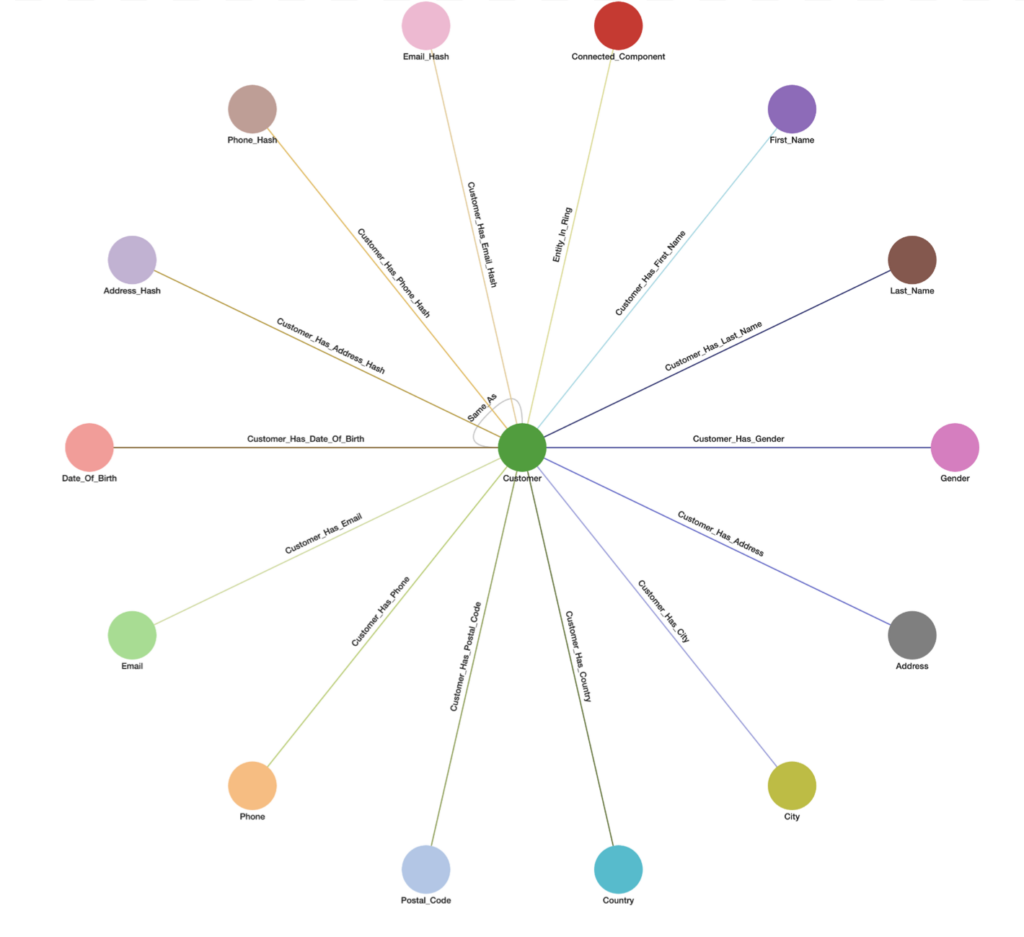
Matching Methods
The solution matches entities based on several criteria. Each criterion translates to its own relational pattern in the graph.
Exact Match
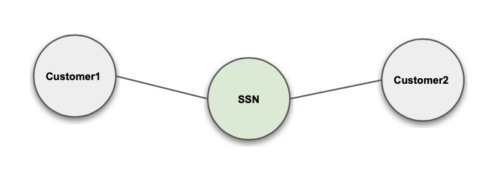
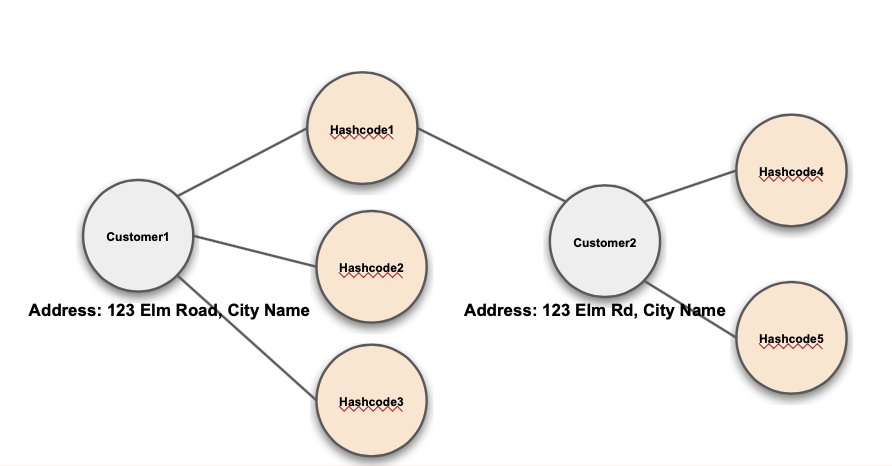
MinHash Fuzzy Match: connects entities using minHash
Metaphone / Soundex Match
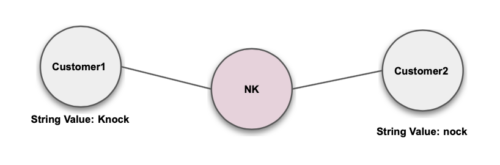
Nickname
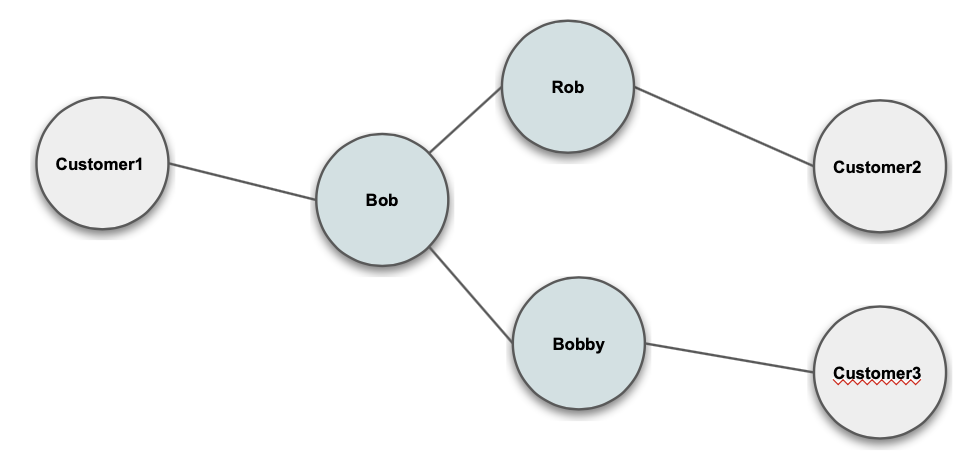
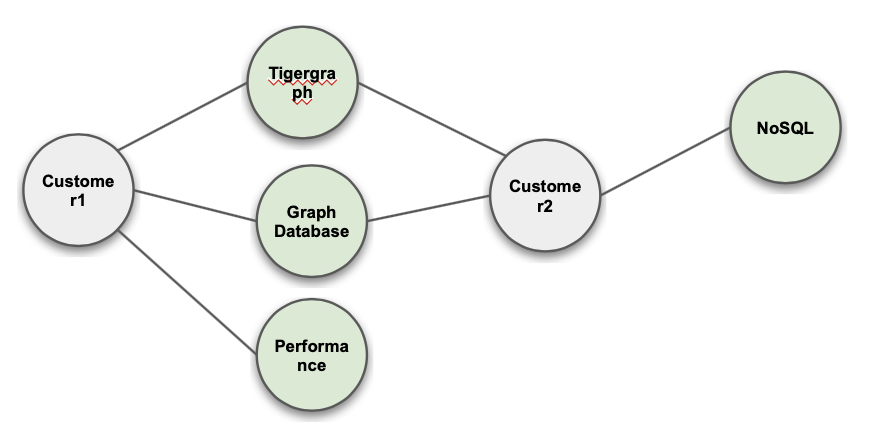
Keyword Extraction
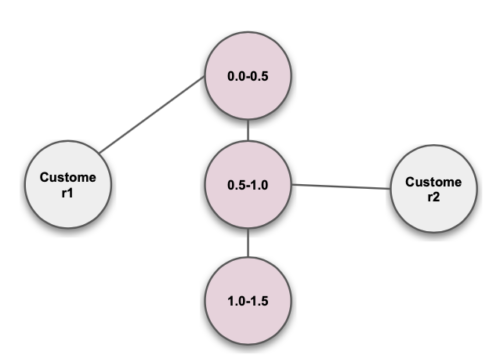
Continuous Value
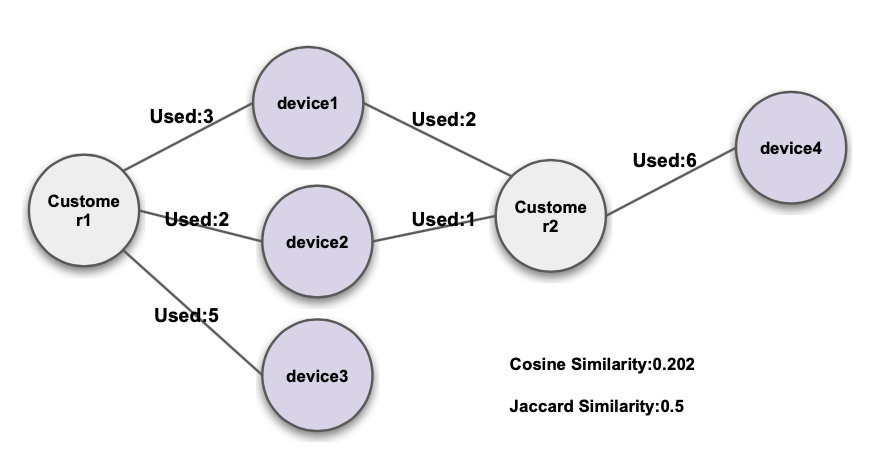
Cosine / Jaccard Similarity
Geo-Location
GSQL Queries & Endpoints
The solution is then implemented as a series of GSQL graph queries.
- delete_all_connected_componentsFirst query executed as part of the full graph Entity Resolution process to remove all existing Connected_Component relationships so these can be fully reset.
- match_entitiesBatch Weakly Connected Components (WCC) algorithm query executed as part of the full graph Entity Resolution process to match all entities using the predetermined matching logic with dynamic weighting per attribute and threshold parameters. After this query completes any matching entities will be connected with a “Same_As” edge in the graph.
- unify_entitiesThird and final query executed as part of the full graph Entity Resolution process to assign all entities in the graph into a Connected_Component vertex. After this query completes all entities connected with a Same_As edge from the previous matching step will be assigned to a common Connected_Component community in the graph and any entities unable to be matched will be assigned to their own distinct Connected_Component community.
- incremental_er (Real-Time ER)Approximate Weakly Connected Components (WCC) algorithm query executed as part of real time Entity Resolution process accepting JSON payload of all entity and PII vertex values which is upserted to the graph and returns boolean entity_resolution status indicating if incoming payload matches with any existing entities in near real time. If matching happens the new entity will be added to the respective Connected_Component after this query completes. If matching does not happen the new entity will be added to a Connected_Component following the next full graph Entity Resolution process.
- distance_and_path_to_XXX
where XXX is other entity(ies) with attribute such as “fraud_status == True”Optional query executed as part of real time Entity Resolution and following incremental_er accepting entity vertex (expected to use the same entity as previous incremental_er query) as input and returns graph features including distance and path to nearest entity(ies) up to configurable amount of maximum hops away with a particular attribute such as fraud_status is True.</>
- get_cc_statsOptional query executed as part of real time Entity Resolution and following incremental_er accepting entity vertex (expected to use the same entity as previous incremental_er query) as input and returns graph features on the associated Connected_Component such as number of unique entities, each node, how many entities are connected by PII attributes, etc.
Integration Interaction Pattern
The full graph Entity Resolution process (delete_all_connected_components, match_entities, and unify_entities) is generally run at least daily but can be run more often such as hourly or every X hours per day. The real time Entity Resolution process (incremental_er, distance_and_path_to_, and get_cc_stats is event driven to enhance real time decision making models with graph features for financial application approvals/denials or other entities/labels etc.
Conclusion
In the dynamic arena of Anti-Money Laundering (AML), the conventional rule-based approach to spotting potential financial crimes is yielding to the transformative potential of graph machine learning. The escalating volume of financial transactions and the prevalence of false positive alerts have catalyzed the adoption of innovative techniques that prioritize investigation efficiency. Graph machine learning, with its ability to decipher intricate relationships between entities in financial data, emerges as a pivotal solution. By leveraging graph features and advanced Graph Neural Networks, institutions can not only mitigate false positives but also enhance investigative accuracy. In this landscape, TigerGraph’s prowess shines – its scalability and performance in generating graph features have positioned it as a leader. As financial institutions navigate the complex terrain of AML, the convergence of graph machine learning and TigerGraph’s capabilities promises a more resilient defense against money laundering while optimizing resource allocation for investigations.
Download TigerGraph’s O’Reilly book Graph-Powered Analytics and Machine Learning. This book uses use case examples, including entity resolution and financial crime detection, to teach about graph analytics and graph machine learning. The examples in the book can be tried for free on TigerGraph Cloud.
