

Entity Resolution With TigerGraph
Marketers with bad data
Wasted marketing budget
Reasons why entity resolution matters
Entity Resolution Challenges Are Blocking Revenue Growth
Modern enterprises face a critical entity resolution problem: the proliferation of various enterprise systems has created multiple, conflicting records for the same customers, products, and business entities. Every client-facing and back-office system—including CMS, CRM, ERP, and marketing automation platforms—maintains separate customer profiles with overlapping but inconsistent information.These fragmented entity records include transaction data such as orders, policies, payments, and claims, as well as interaction data from customer service calls, website visits, and physical store engagements. The core entity resolution challenge emerges when the same customer appears as “John Smith” in one system, “J. Smith” in another, and “Jonathan Smith” in a third, each with slightly different contact information or account details.
The lack of effective entity resolution software has created a data nightmare where master data elements like names, addresses, and phone numbers exist in multiple, conflicting versions across systems.
The business impact of unresolved entity resolution problems follows the 1-10-100 rule: it costs $1 to verify an entity record as it’s entered, $10 to resolve entity conflicts later, and $100 if entity resolution issues are left unaddressed.
Read More
What Is Entity Resolution and Why Legacy Approaches Fall Short
Entity resolution is the process of identifying and linking records that refer to the same real-world entity across different data sources. Traditional master data management systems are built upon relational databases, which store information such as account, contact, lead, campaign, and opportunity in separate tables, one for each type of business entity.
These relational databases are good tools for indexing and searching for data, as well as for supporting transactions and performing basic analysis. However, conventional entity resolution software is poorly-equipped to deal with the deluge of data that results in multiple data entries for a single real-world entity, particularly when real time entity resolution is required.
In this environment of ambiguous data, analysts need to join a number of large tables to run the queries and collect the data for analysis. Such queries could take hours or even days to run, rendering any meaningful analysis of the patterns practically impossible and making real time entity resolution nearly unattainable with traditional approaches.
Read More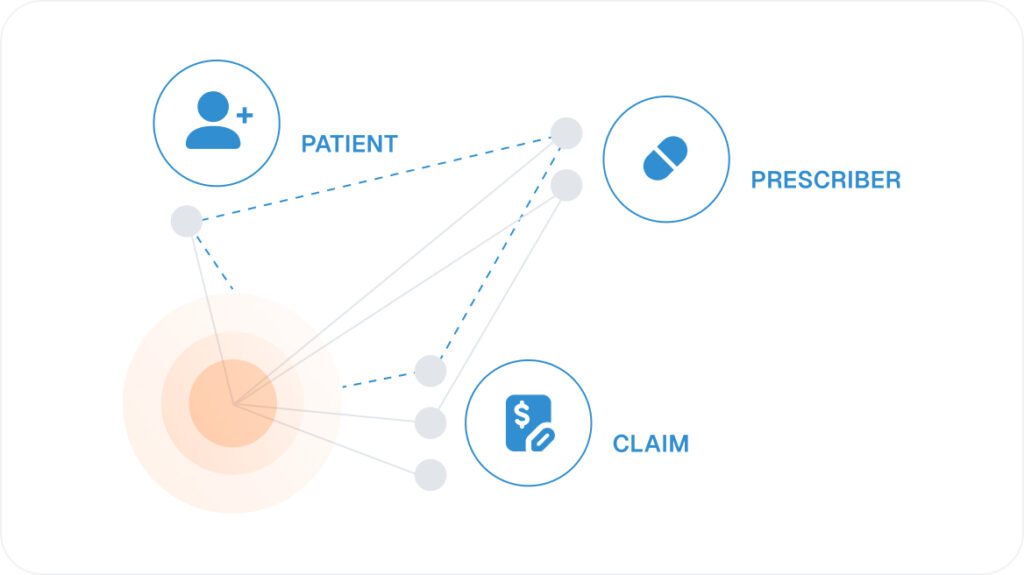

Graph Databases for Entity Resolution: The Ideal Solution
Graph databases are purpose-built for entity resolution solutions, making them superior to traditional approaches. Merging customer data from multiple data sources is not always easy with conventional systems. One challenge is the entity resolution process itself—deciding when multiple entities from different data sources actually represent the same real-world entity and then merging them into one unified record.
Consider an example where there are three data sources containing the following types of customer information:
- Source1 (SSN, Email, Address)
- Source2 (SSN, Phone, Name, Age)
- Source3 (Email, Phone, Gender)
Let’s assume that SSN, Email, and Phone are each sufficient to uniquely identify an individual (that is, they constitute PII, personally identifiable information). The problem is that the different sources use different identifiers, and that individual records might be missing some information. Over time, missing PII of a customer may show up later in another data source. The goal is to use whatever PII we have about a customer to find all information (attributes) of a customer across all data sources and build a unified record with the following attributes: Customer (SSN, Email, Phone, Name, Age, Gender, Address).
Read More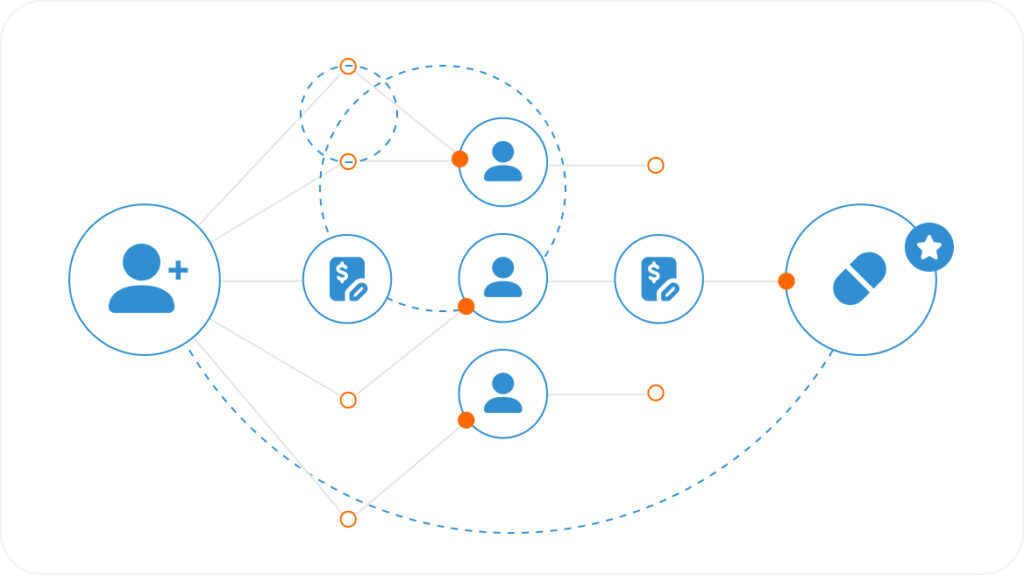
FAQ
Entity resolution is the process of identifying, matching, and merging records that refer to the same real-world entity (such as a customer, product, or organization) across different data sources and systems. It’s critical for businesses because duplicate and inconsistent entity records lead to inaccurate analytics, ineffective marketing campaigns, compliance risks, and poor customer experiences. Without proper entity resolution, companies cannot achieve a single, accurate view of their customers or business entities.
Graph databases excel at entity resolution because they naturally model relationships between entities and their attributes. Unlike relational databases that store data in separate tables requiring complex joins, graph databases store entities as vertices connected by edges, making it easier to identify matching entities across multiple data sources. Graph databases can perform real time entity resolution by instantly traversing connections between entities and their shared attributes (like email addresses, phone numbers, or addresses) to find matches.
TigerGraph’s entity resolution graph database solution provides several key advantages: it supports real time entity resolution at scale, handles complex matching rules across multiple attributes, maintains data lineage for compliance, and can process billions of entities with sub-second response times. TigerGraph’s graph entity resolution algorithms can identify both direct matches (same email address) and indirect matches (shared address + similar name variations) that traditional systems often miss.
Yes, advanced entity resolution solutions like TigerGraph incorporate sophisticated fuzzy matching algorithms that can identify entities even when data contains typos, abbreviations, formatting differences, or incomplete information. The graph database approach allows for probabilistic matching based on multiple similarity scores across different attributes, enabling more accurate entity resolution even with poor quality data.
Real time entity resolution enables businesses to immediately identify returning customers across channels, prevent duplicate account creation, detect fraud as it happens, and provide personalized experiences based on complete customer profiles. This immediate entity matching capability eliminates the delays associated with traditional batch processing approaches and ensures that customer-facing systems always have access to the most current, unified entity information.
The primary challenges include handling massive data volumes from multiple sources, managing complex business rules for different entity types, ensuring data privacy and compliance, maintaining performance as data grows, and dealing with constantly changing data schemas. A graph database for entity resolution addresses these challenges through its scalable architecture, flexible schema design, and optimized algorithms for large-scale entity matching operations.
Entity resolution solutions help organizations maintain compliance by providing complete audit trails of data lineage, enabling accurate data subject identification for privacy requests, ensuring consistent data handling across systems, and supporting data retention policies. TigerGraph’s entity resolution capabilities maintain detailed records of data sources, transformation rules, and merge decisions, which are essential for GDPR, CCPA, and other regulatory requirements.
