Traditional Data Analytics, Flying Blind
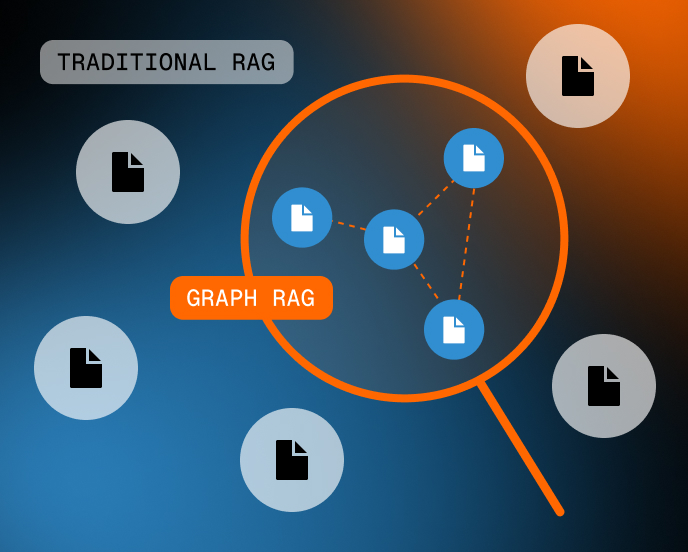
Traditional analytics only shows isolated data points and historical trends. Requires complex joins and multiple queries to understand relationships. Limited to 2-3 hop analysis before performance degrades. Literally unable to see how everything connects.