

TigerGraph Database Products Overview
Advanced Analytics and Machine Learning on Connected Data
Gets the Answers You Need
Challenge
Struggling to answer key business questions despite having lots of data? You’re not alone. Traditional tools often give late or incorrect answers, leaving a gap between needed insights and crucial decisions.

Solution
TigerGraph connects your data to the answers you need. It analyzes data at scale, runs real-time queries, provides in-database analytics, and boosts your ML and AI solutions.


TigerGraph Advantages

Digital Transformation
Break free from legacy systems, optimize your IT processes, on premises or cloud, and foster a culture of innovation and productivity. Utilize low-code/no-code development tools, visualization tools, and Solution Kits.

Seamless Connectivity
Connect graph analytics into your application workflows faster, ensuring real-time data analytics with 20% greater accuracy while achieving 3X application user efficiency.

Eliminating Data Silos
Organize, correlate, and connect multiple sources of data. With TigerGraph, unify your data landscape and enable seamless data flow across your organization.

Faster and More Accurate Data-Driven Outcomes
Achieve 40X faster time-to-market and up to 600X ROI with our graph and AI-powered insights, transforming your data into a strategic asset.




TigerGraph Products
Tools and Products Available on TigerGraph Databases


Graph Data Science Algorithm Library
Open-source library of graph algorithms, run in-database…
Discover

Solution Kits
Comprehensive, ready-to-use industry specific solutions that package schemas, queries…
Discover
ML Workbench
Enables data scientists to develop graph-based ML models using production-scale data in TigerGraph…

Meet the Product
See the capabilities and use cases currently in production across industries such as banking, manufacturing, pharmaceutical, retail, telecom and more.

Use Cases
TigerGraph’s graph-powered analytics and ML/AI of any size is the engine behind smarter and more effective solutions at some of the world’s leading companies.
With graphs and AI-powered integration, achieve 40x faster time-to-market and up to
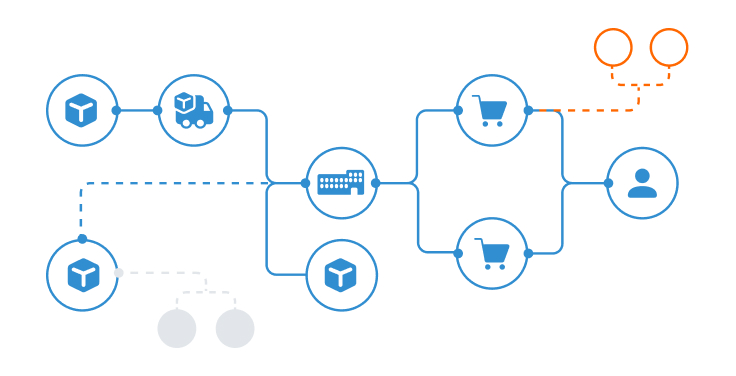
Supply Chain and Data Center Digital Twins
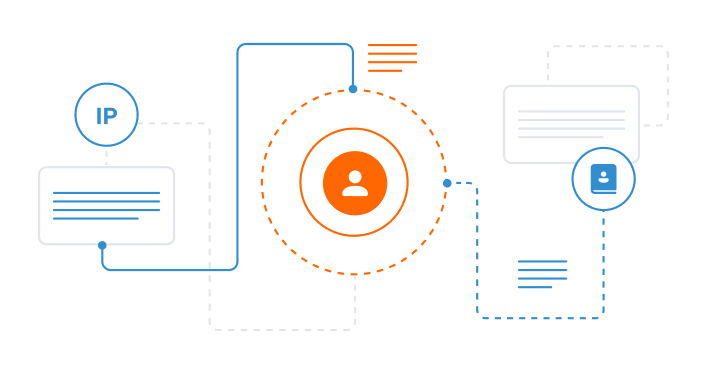
Customer Intelligence
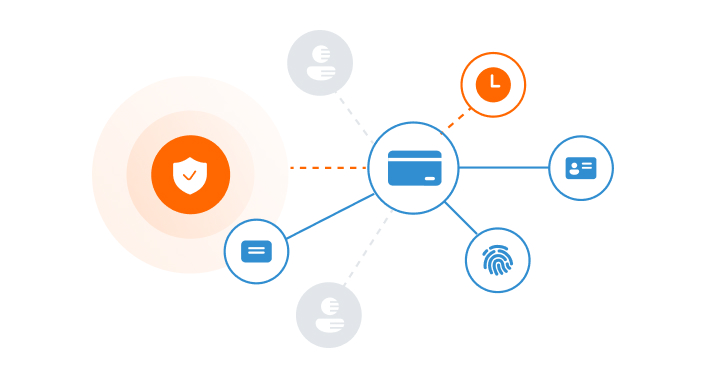
Anti-Fraud & Anti-Money Laundering
Success Stories






Learn more. Get inspired.
Read Documentation
TigerGraph University
Join the Community
