

Introduction to Large Language Models
Generative AI and Large Language Models are on everyone’s mind – they have been proven to be very useful tools for general purpose information found on the internet. However, businesses are left with the question: how can they ask questions about their data? What if they want a question answered about John Doe’s different financial opportunities given their account status? What if a doctor wants to bounce ideas off of a digital assistant surrounding what care path best fits Maria’s needs and prior health history? Organizations need to enable LLMs to reason with sensitive data that can never be incorporated into a training dataset due to the risk of leaking sensitive information. Additionally, LLMs need ground-truth facts in order to provide correct answers.
So how does the financial analyst or the doctor get their answers? The LLM has to retrieve information from a source of ground-truth data, and reason with that data passed to it. Maybe one could hypothesize passing all of John’s account statements or Maria’s clinical notes to the model, and it would figure it out, but unfortunately this is not the case. Since LLMs are neural networks, they operate on a fixed-size input. That means that users are limited by how much data they can pass into the model at a time, known as a context length. Another way to put this is LLMs have a limited number of tokens that they can take at once. Additionally, LLM API providers such as OpenAI charge businesses by their token usage, and therefore businesses want to limit the amount of data they pass to the model, and still get high quality results. This is where highly scalable, deduplicated, and relationship-rich external data sources come in – LLMs can reason and interact with these data sources in a token-efficient manner by calling APIs to get the exact data they need to answer the question, rather than a customer’s entire history.
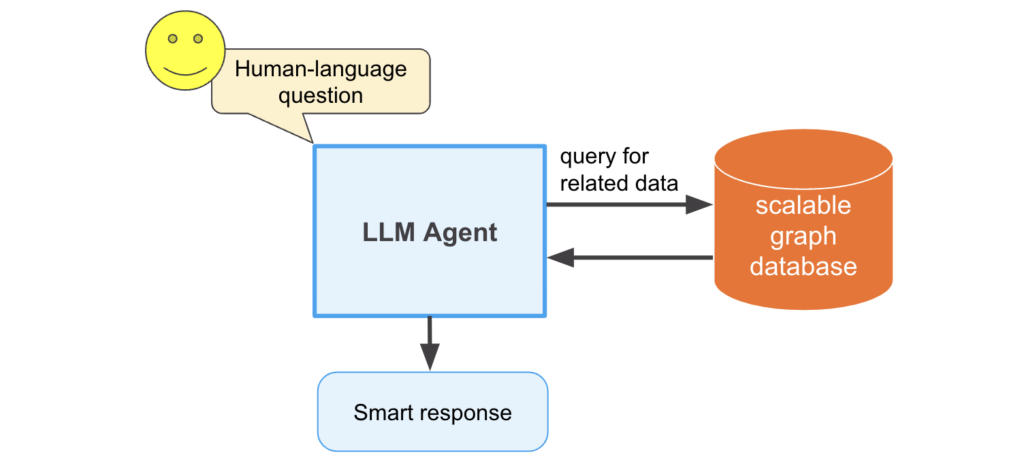
Question-Answering LLM Agent – Graph Data General Architecture
When talking about highly scalable, relationship-rich, and generally deduplicated data sources, graph databases usually come to mind. TigerGraph specifically has the capability to scale beyond 10s of TBs, and many of our customers deduplicate their data via entity resolution algorithms run within the database. Graphs in general naturally fit the relationship-rich data that LLMs can reason very well with. Additionally, TigerGraph allows for the scalable execution of graph algorithms that can abstract questions such as the influence or communities of entities within the database. The next question is, how can we link the power of TigerGraph with these LLM agents?
Integrate LLMs with TigerGraph With LangChain
LangChain is a Python library that integrates Large Language Models (LLMs) such as OpenAI’s GPT models and Google’s BARD models, among others. There are many benefits to linking a natural language interface to graph databases such as TigerGraph, as the agent’s response can include data retrieved from the database, ensuring the model has up-to-date information. This reduces the chances of these model’s responses to be inaccurate, known as hallucination.
In this demo, we are going to integrate LangChain with the Python driver of TigerGraph, pyTigerGraph. We will build up various LangChain tools in order for the LLMs to best extract the information from the database. For the full code, check out the notebook here: https://github.com/tigergraph/graph-ml-notebooks/blob/main/applications/large_language_models/TigerGraph_LangChain_Demo.ipynb.
LangChain Tools
LangChain allows LLMs to interact with the “real-world” through things known as tools. By creating new LangChain tools, developers can connect various data sources into the LLM’s environment, reducing the number of hallucinations and allowing them to answer questions whose answers were not present in their training datasets. In the accompanying notebook, you can see three tools built for interacting with TigerGraph: MapQuestionToSchema, GenerateFunction, and ExecuteFunction.
Agent Workflow
LangChain wraps a LLM into an agent, which can reason and perform sequences of tasks on its own. In this case of integration with the database, the same general flow of execution is performed by the agent regardless of the question asked of it. First, the question is mapped to the graph’s schema using the tool MapQuestionToSchema. Then, the standardized question is passed to the GenerateFunction tool which populates the correct pyTigerGraph function call to run on the database. Finally, that function call is run in the ExecuteFunction tool. This returns the JSON response from the database’s REST endpoints, which is then parsed by the agent and states the answer in natural English.
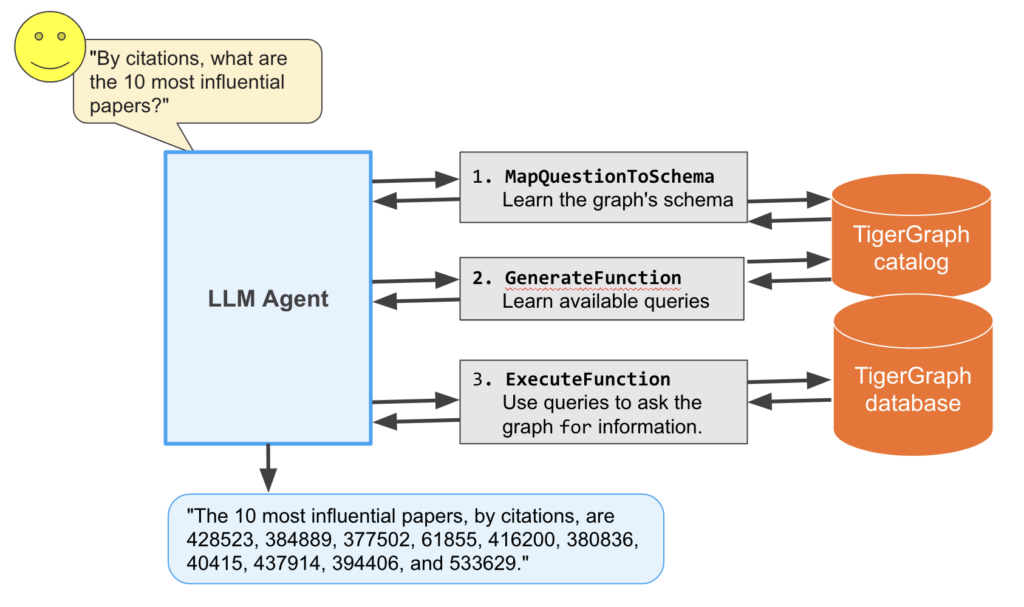
Question-Answering LLM Agent – TigerGraph Pipeline
The MapQuestionToSchema and GenerateFunction tools actually use another LLM call within their execution. MapQuestionToSchema asks a LLM to translate the user’s question to utilize standard schema elements. For example, if there is a vertex type of “Institution” and the user asks “How many universities are there?”, the tool will return the question “How many Institution vertices are there?” The LLM within the tool automatically converts synonyms of schema elements into their normalized form. GenerateFunction then uses another LLM to create the pyTigerGraph function call. Continuing the example, the question “How many Institution vertices are there?” will then be converted to “getVertexCount(“Institution”)”, which is the valid pyTigerGraph function to count the number of institutions in the graph. This output is then executed in the ExecuteFunction tool.

Example Questions (and Answers)
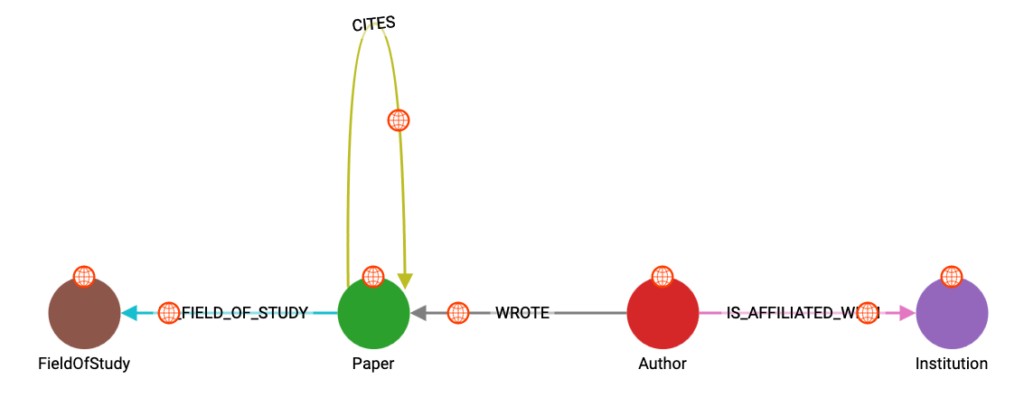
Using the OGB MAG dataset, we can ask the LangChain agent questions about the data. The schema includes information about papers, authors, topics, and institutions, with the relationships shown in the schema below.
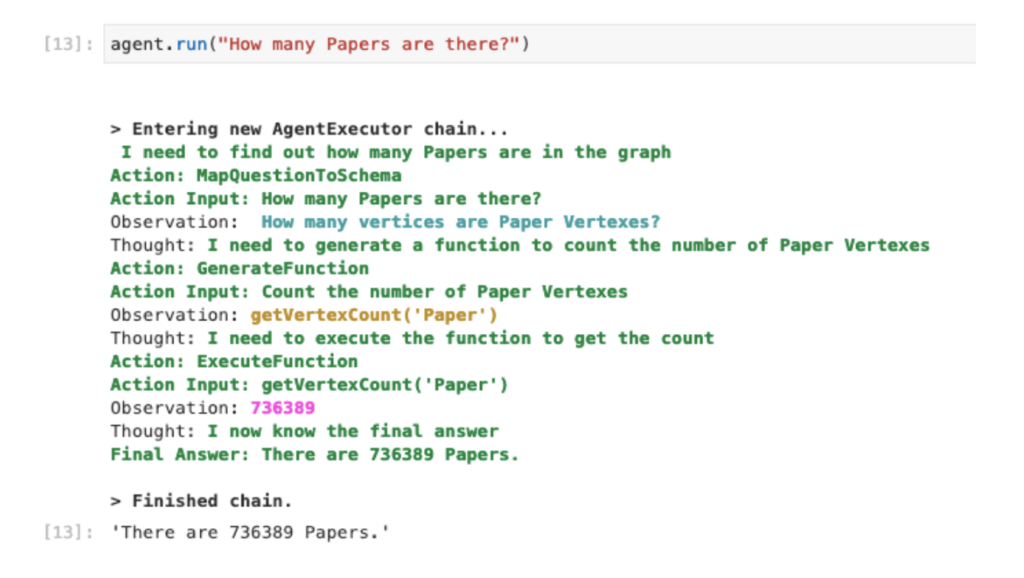
We are going to start with some simple ones, such as asking how many papers are in the data:
When more complex queries and algorithms are installed, we can start asking more questions about how entities interact with each other in the graph.
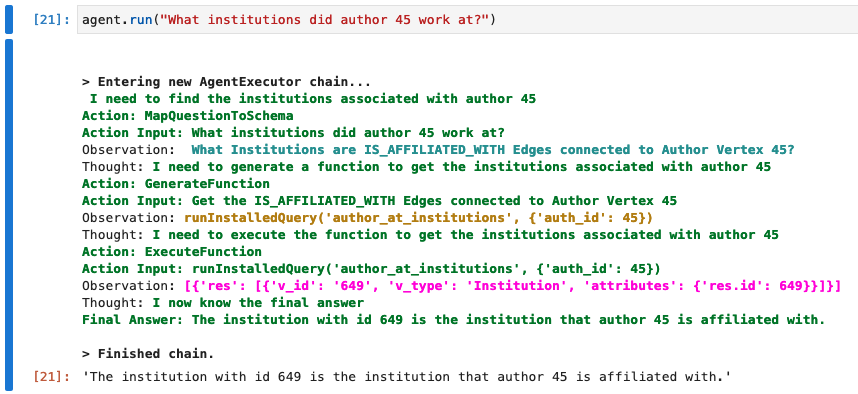
We can even ask an abstract question such as the most influential papers:
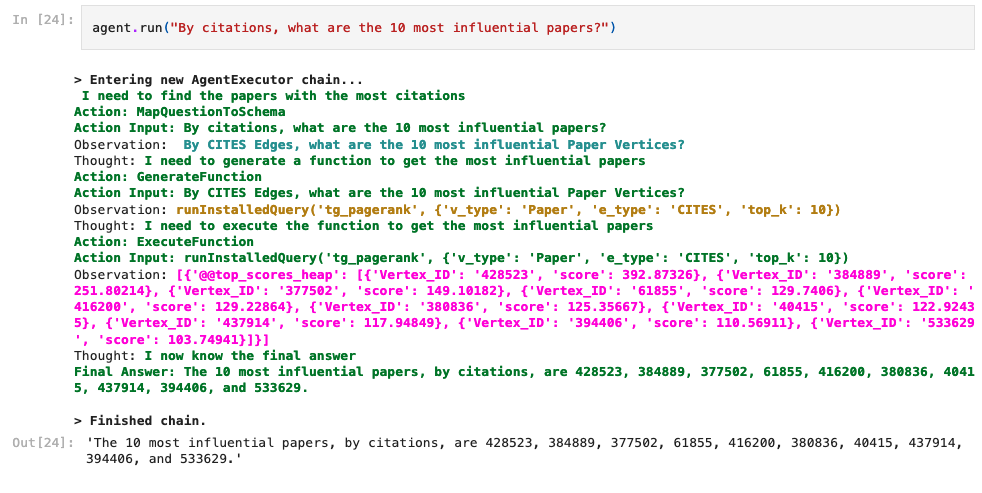
The agent recognizes that PageRank is a query available to it and that it is a measure of influence. Then, it calls it like any other query and returns the results!
Conclusion
Integrating LLMs and TigerGraph combine the best of both worlds: the reasoning and natural language capabilities of LLMs enabled by up-to-date and rich data representations provided by TigerGraph. Through the data’s representation in a graph format, the LLM can answer very complex and abstract questions, such as: find the most influential research papers, or detect a community of bad actors in a financial graph. This integration opens the door to enabling business analysts to be more productive and have richer information at their fingertips. This demo is just the beginning though; stay tuned for future updates that continue to enrich the connection between natural language and TigerGraph.
Want to try this for yourself? Get TigerGraph Cloud for Free and then add our Python library pyTigerGraph to your server.
