Products
TigerGraph Savanna
TIGERGRAPH DB
Community Edition
AI & Graph Intelligence
Agentic AI
GraphRAG
Hybrid Graph + Vector Search
Graph Data Science Library
Languages and Tools
Solution Kits
GSQL Query Language
openCypher Query Language
GraphStudio
Insights
Connectors
Compare Editions
Solutions
Solutions
Solutions Overview
Increase revenue
Product Marketing
Customer 360
Entity Resolution
Recommendation Engine
Manage risk
Fraud Detection and Protection
Cybersecurity Threat Detection
Anti-Money Laundering (AML)
Risk Assessment and Monitoring
Improve operations
Supply Chain Analysis
Network Optimization
Energy Management System
By industry
Advertising, Media, Entertainment
Financial Services
Healthcare & Life Sciences
Foundational
AI & Machine Learning
Time Series Analysis
Geospatial Analysis
Developers
Download
TigerGraph DB
TigerGraph Docker Image
GSQL Client
Developers
Documentation
Developer Hub
Ecosystem
Community Forum
Resources
Blog
TigerGraph Blog
Resources
Demos
Webinars & Events
Videos & Podcasts
Benchmarks
Reports & Whitepapers
Datasheets
Glossary
Pricing
Services
Services and Support
TigerGraph University
Training & Certifications
TigerGraph Support
Documentation
Production Guidelines
Company
Company
Company Overview
Leadership
Legal Terms
Patents
Security and Compliance
Careers
Join Us
Open Positions
Customers
Ford
Intuit
Jaguar Land Rover
Xbox
Read more success stories
Press Room
News and Press Releases
Awards
Partners
Partner Benefits
TigerGraph Partners
Contact Us
Products
TigerGraph Savanna
TIGERGRAPH DB
Community Edition
AI & Graph Intelligence
Agentic AI
GraphRAG
Hybrid Graph + Vector Search
Graph Data Science Library
Languages and Tools
Solution Kits
GSQL Query Language
openCypher Query Language
GraphStudio
Insights
Connectors
Compare Editions
Solutions
Solutions
Solutions Overview
Increase revenue
Product Marketing
Customer 360
Entity Resolution
Recommendation Engine
Manage risk
Fraud Detection and Protection
Cybersecurity Threat Detection
Anti-Money Laundering (AML)
Risk Assessment and Monitoring
Improve operations
Supply Chain Analysis
Network Optimization
Energy Management System
By industry
Advertising, Media, Entertainment
Financial Services
Healthcare & Life Sciences
Foundational
AI & Machine Learning
Time Series Analysis
Geospatial Analysis
Developers
Download
TigerGraph DB
TigerGraph Docker Image
GSQL Client
Developers
Documentation
Developer Hub
Ecosystem
Community Forum
Resources
Blog
TigerGraph Blog
Resources
Demos
Webinars & Events
Videos & Podcasts
Benchmarks
Reports & Whitepapers
Datasheets
Glossary
Pricing
Services
Services and Support
TigerGraph University
Training & Certifications
TigerGraph Support
Documentation
Production Guidelines
Company
Company
Company Overview
Leadership
Legal Terms
Patents
Security and Compliance
Careers
Join Us
Open Positions
Customers
Ford
Intuit
Jaguar Land Rover
Xbox
Read more success stories
Press Room
News and Press Releases
Awards
Partners
Partner Benefits
TigerGraph Partners
Contact Us
Blog
Discover our blog
Graph Analytics
Uncategorized
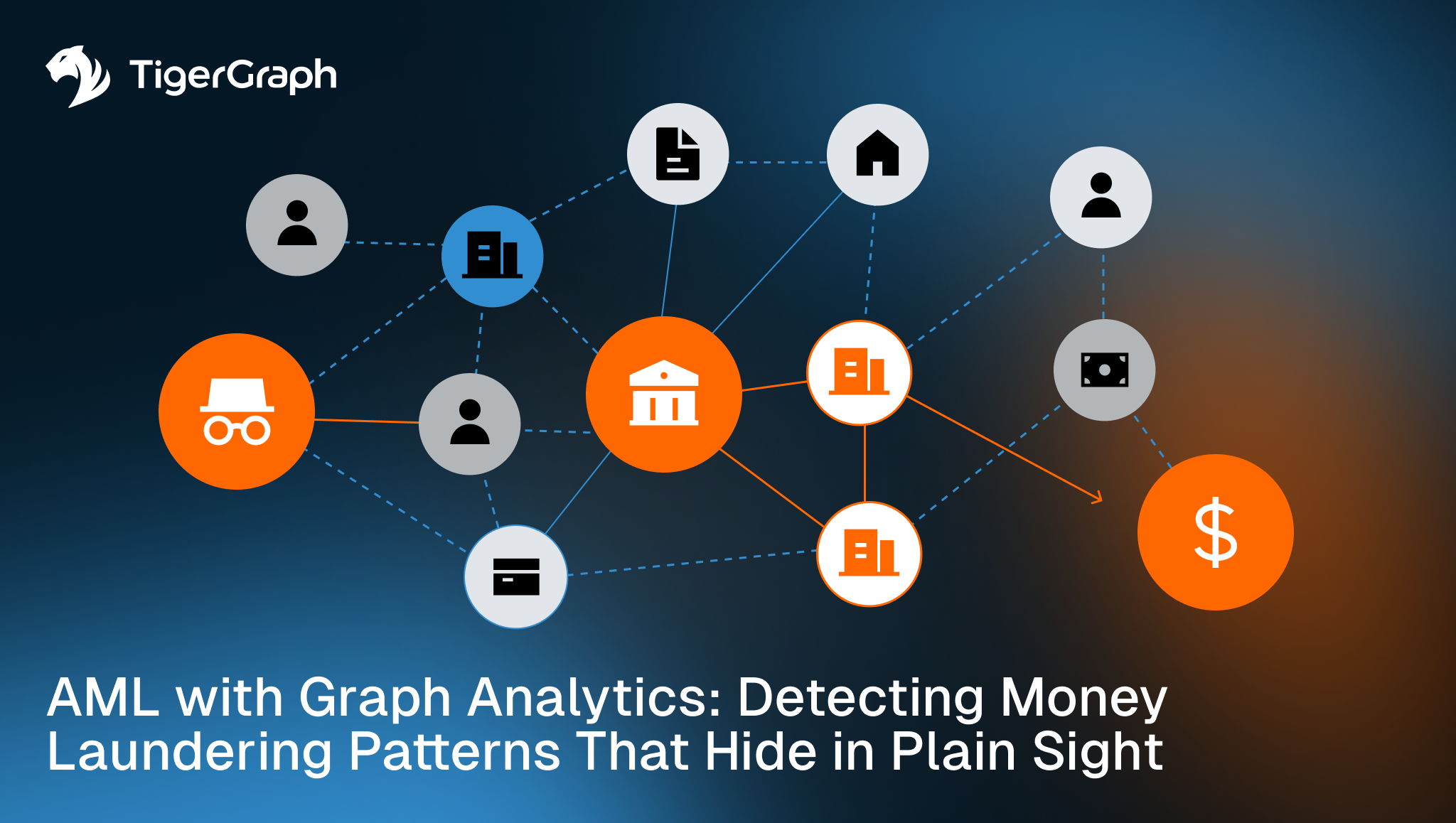
AML with Graph Analytics: Detecting Money Laundering Patterns That Hide in Plain Sight
Discover
Cybersecurity
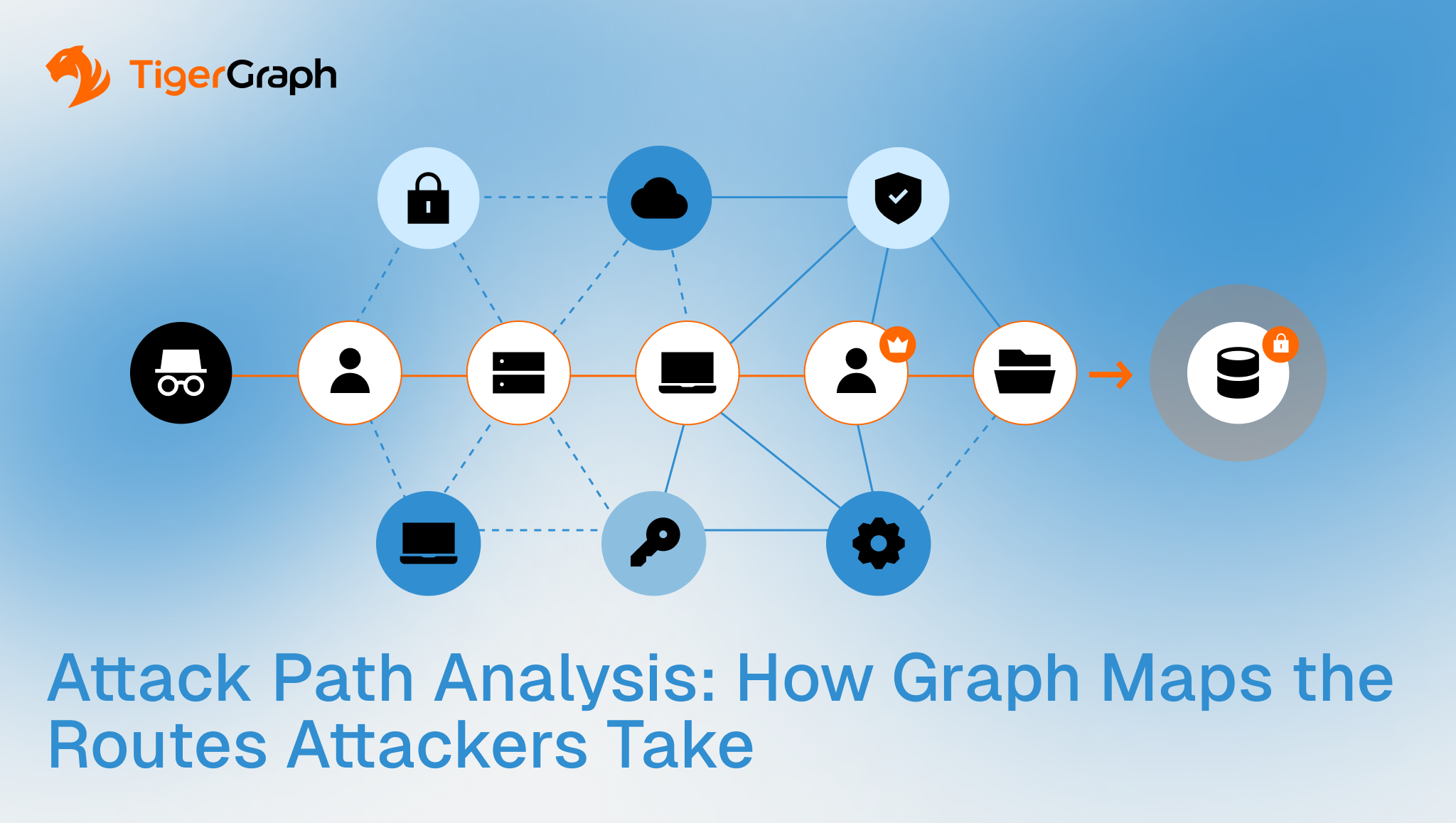
Cyberattack Path Analysis: How Graph Maps the Routes Attackers Take
Discover
GraphRAG
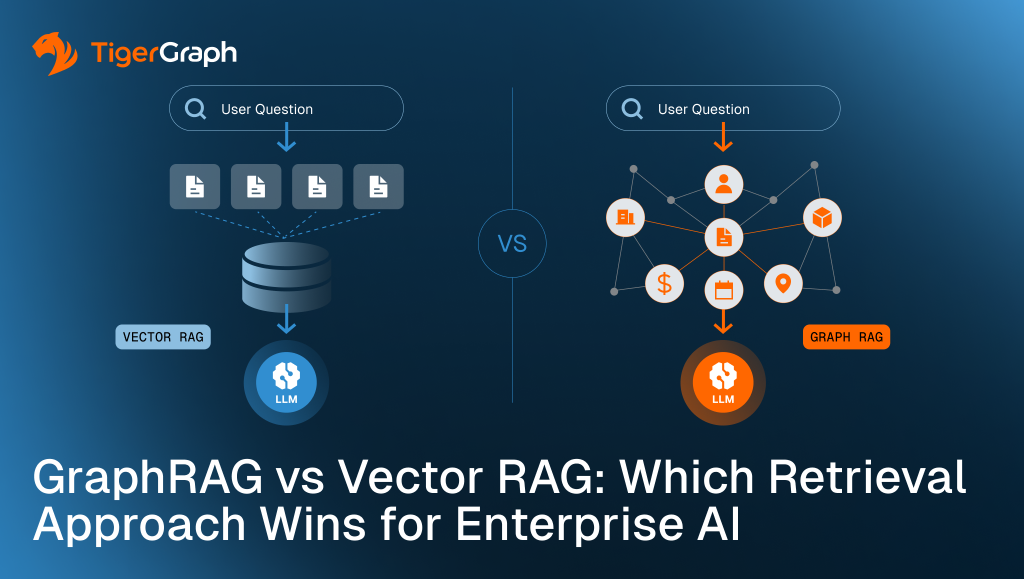
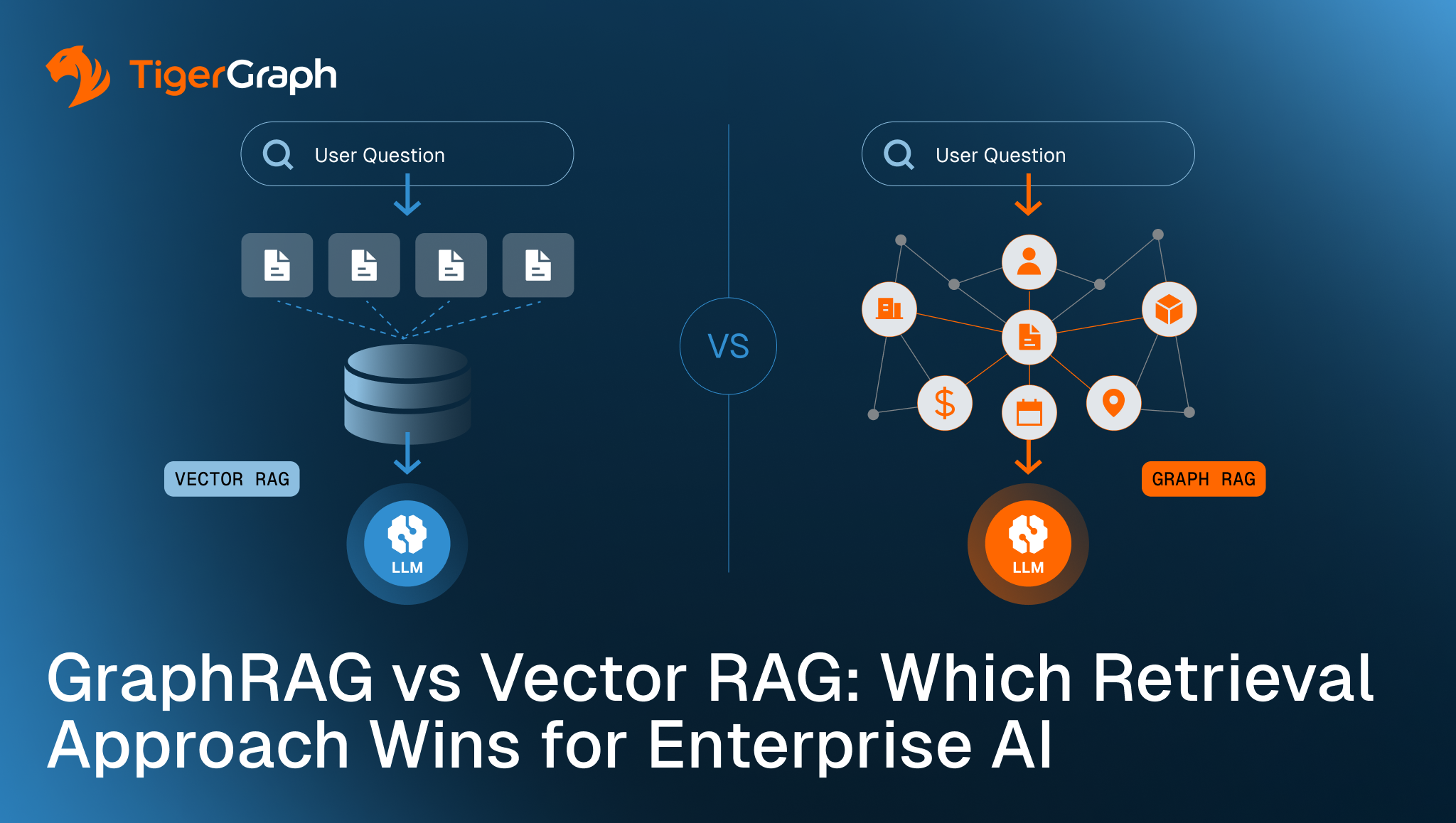
GraphRAG vs Vector RAG: Which Retrieval Approach Wins for Enterprise AI
Discover
Supply Chain
Supply Chain Resilience: How Graph Helps You Bounce Back Faster from Disruption
Discover
Graph Databases Comparison
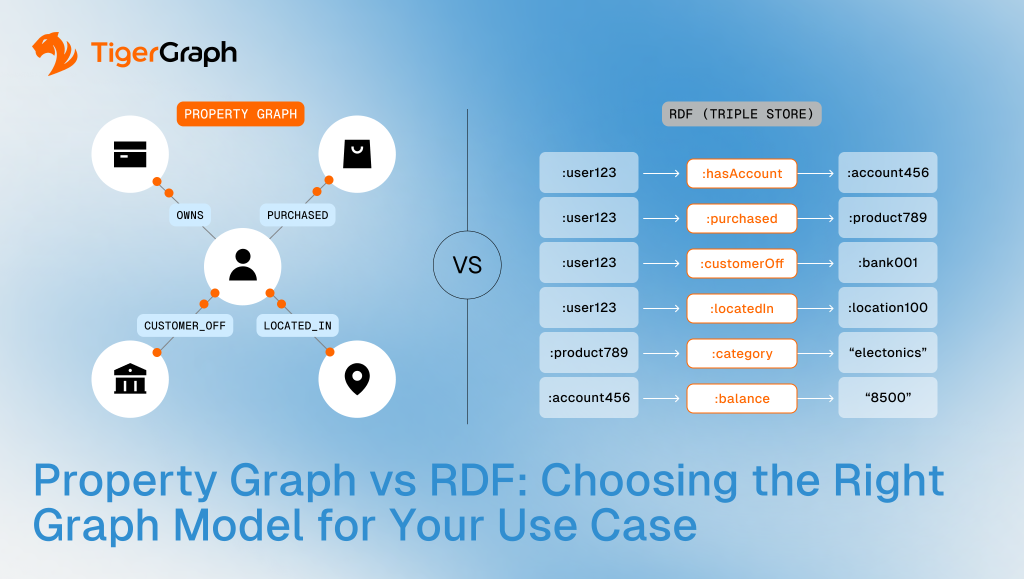
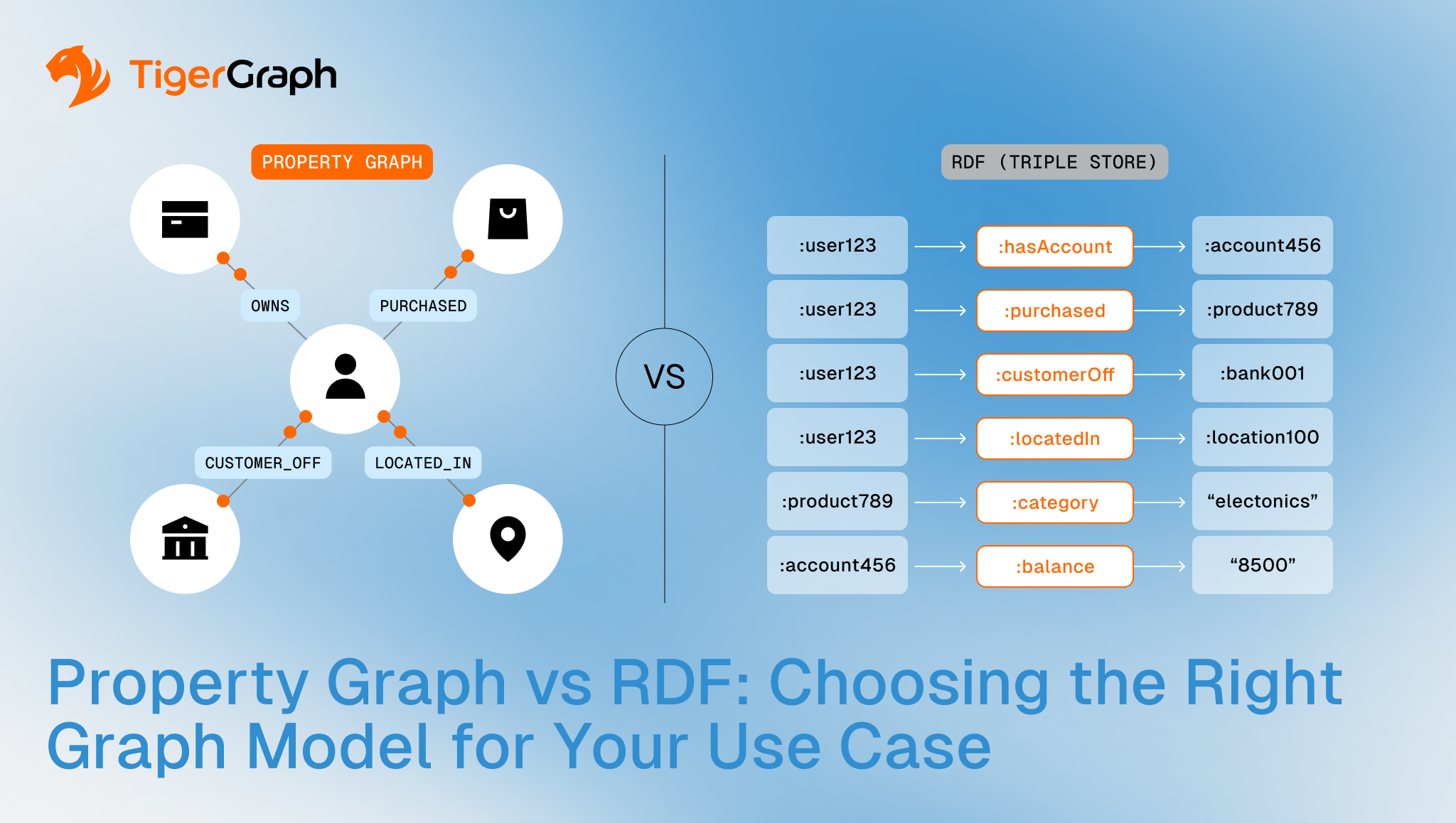
Property Graph vs RDF: Choosing the Right Graph Model for Your Use Case
Discover
Categories
All Categories
About TigerGraph
Benchmark
Business
Community
Compliance
Customer 360
Cybersecurity
Data Science
Developers
Digital Twin
eCommerce
Engineers
Entity Resolution
Finance
Fraud / Anti-Money Laundering
GQL
Graph + AI
Graph Algorithms
Graph Analytics
Graph Databases
Graph Databases Comparison
Graph Neural Networks
GraphRAG
GSQL
Healthcare
KYC risk assessment
Machine Learning / AI
Risk and Fraud Analytics
Supply Chain
TigerGraph
TigerGraph Cloud
Results
Graph Analytics, Uncategorized
Wed 22 Jul 2026
AML with Graph Analytics: Detecting Money Laundering Patterns That Hide in Plain Sight
Discover
Cybersecurity
Wed 22 Jul 2026
Cyberattack Path Analysis: How Graph Maps the Routes Attackers Take
Discover
GraphRAG
Wed 22 Jul 2026
GraphRAG vs Vector RAG: Which Retrieval Approach Wins for Enterprise AI
Discover
Supply Chain
Wed 22 Jul 2026
Supply Chain Resilience: How Graph Helps You Bounce Back Faster from Disruption
Discover
Graph Databases Comparison
Wed 22 Jul 2026
Property Graph vs RDF: Choosing the Right Graph Model for Your Use Case
Discover
Graph Databases, Graph Databases Comparison
Fri 17 Jul 2026
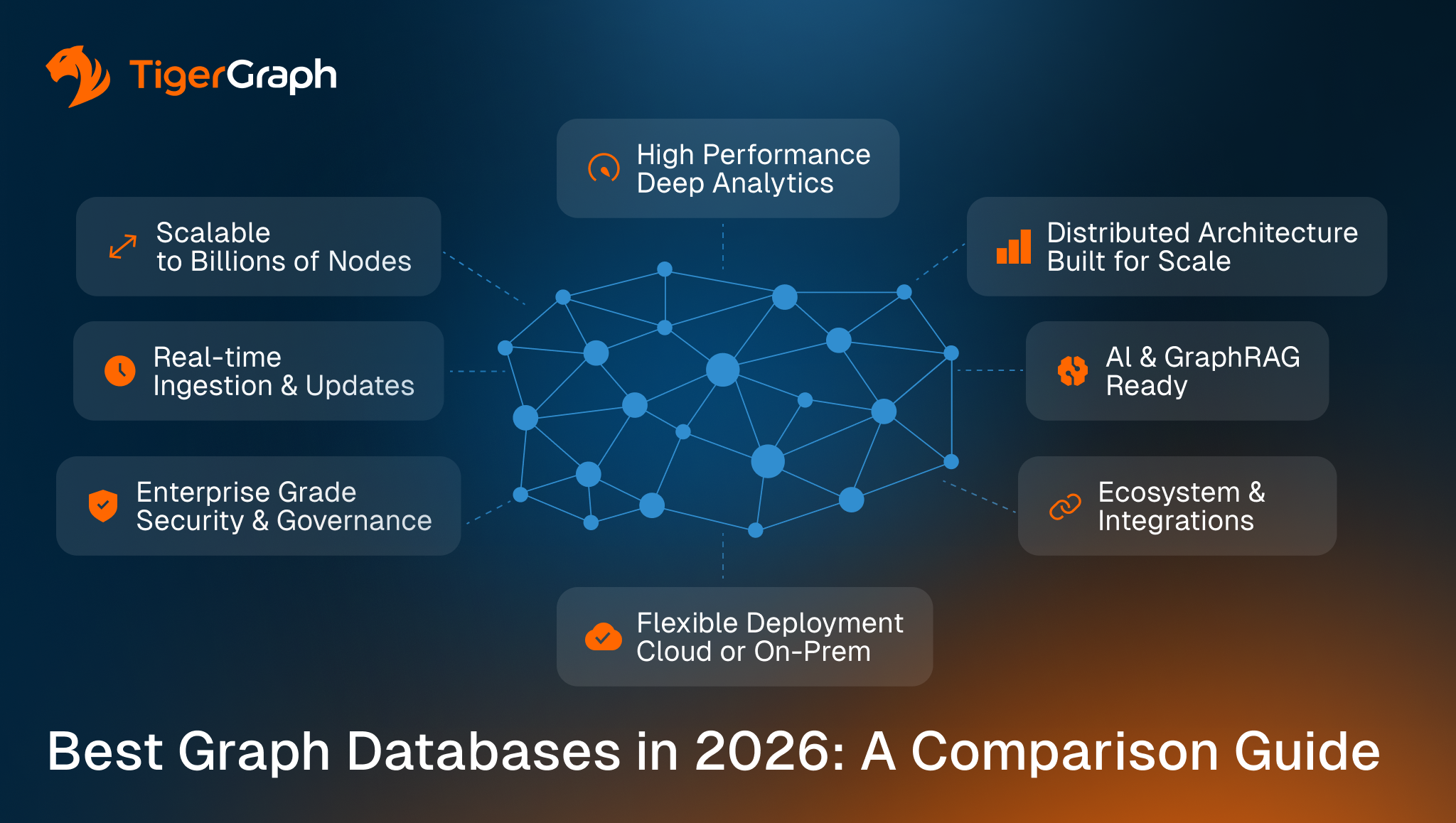
Best Graph Databases in 2026: A Comparison
Discover
Cybersecurity
Fri 17 Jul 2026
Cybersecurity Threat Detection with Graph: Stopping Attacks Before They Spread
Discover
Entity Resolution, Risk and Fraud Analytics
Fri 17 Jul 2026
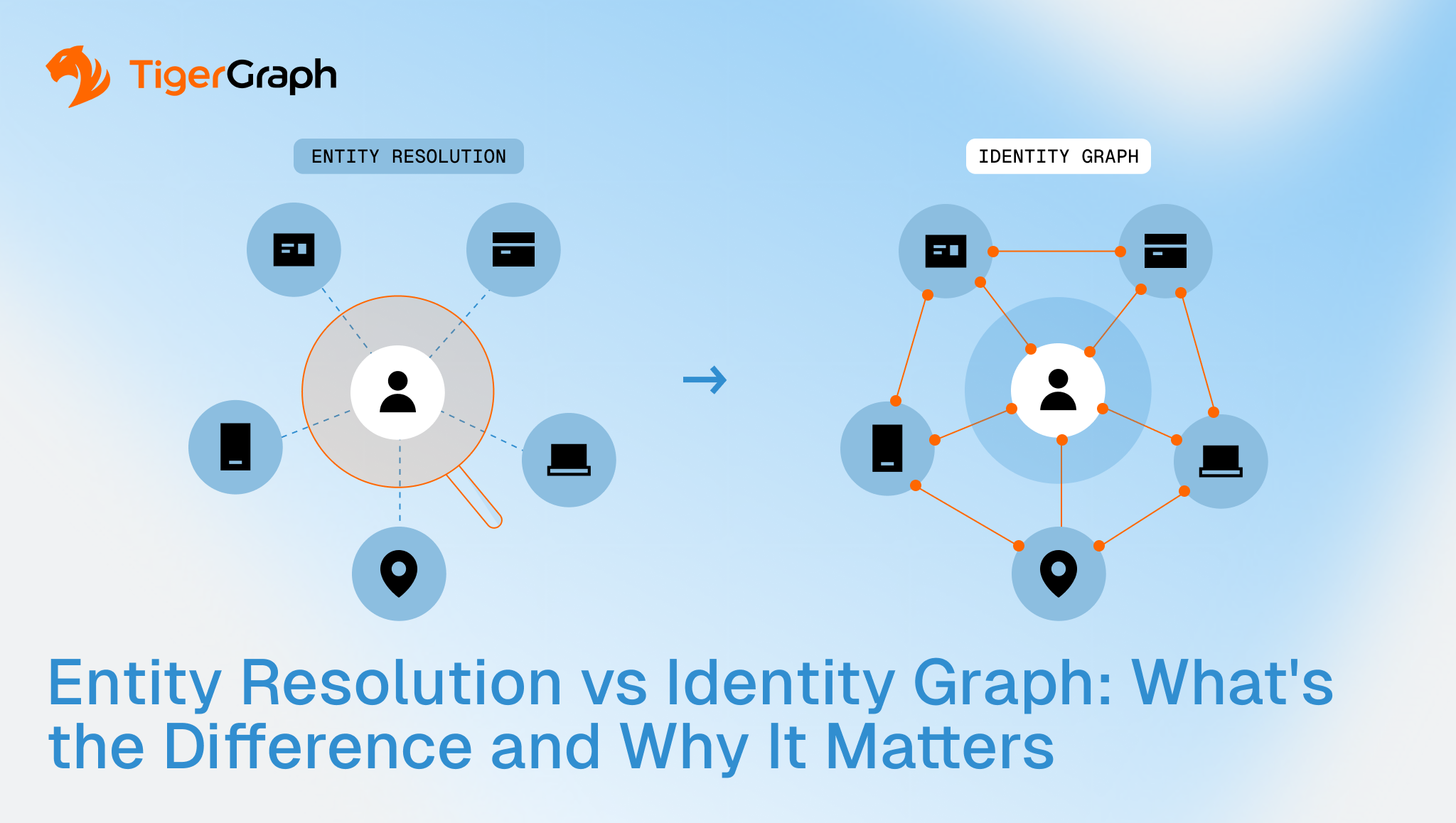
Entity Resolution vs Identity Graph: What’s the Difference and Why It Matters
Discover
Graph + AI, Graph Neural Networks
Fri 17 Jul 2026
Graph Neural Networks Explained: When AI Learns from Connections
Discover
Graph + AI, Graph Neural Networks, GraphRAG
Fri 17 Jul 2026
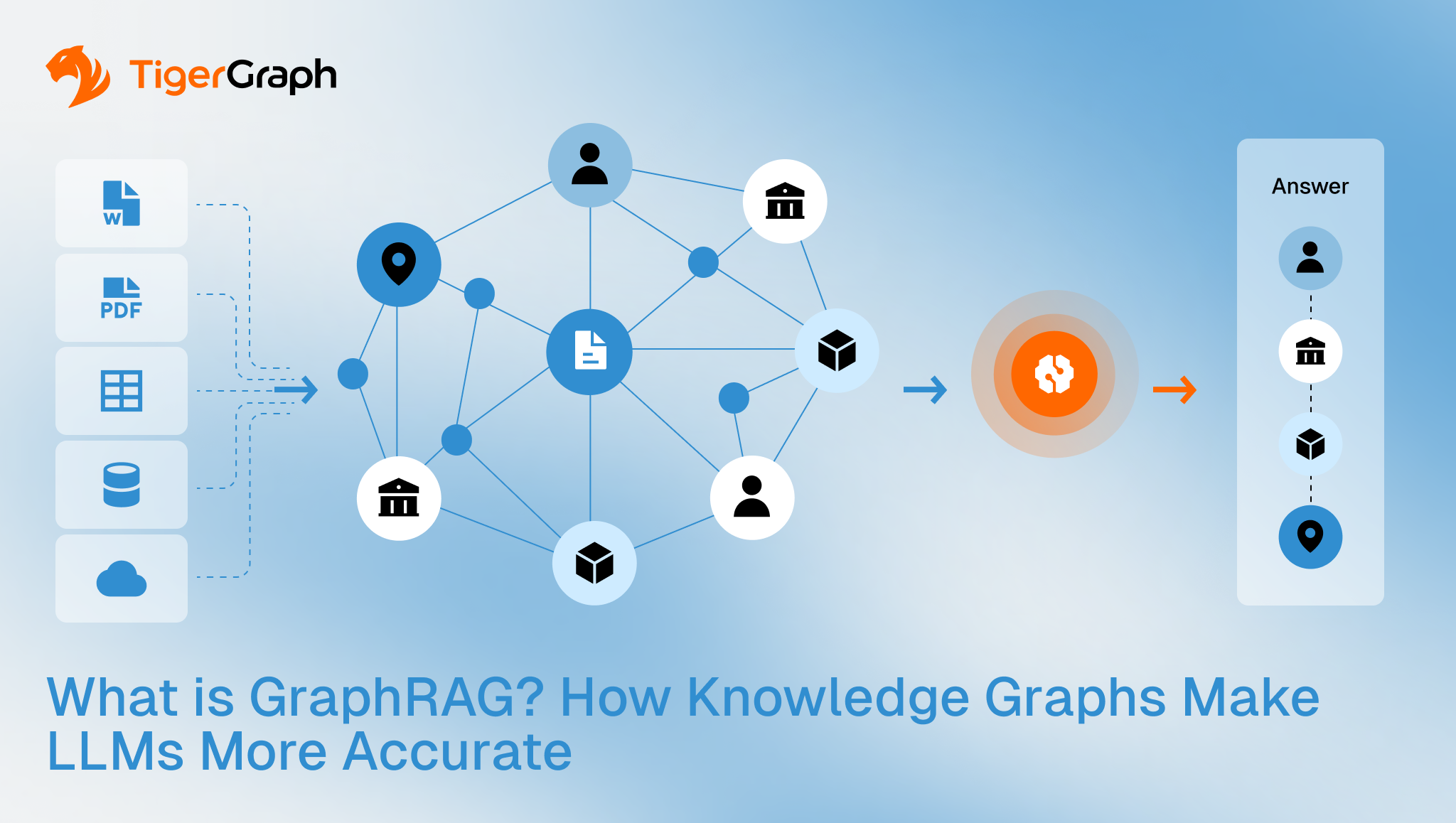
What is GraphRAG? How Knowledge Graphs Make LLMs More Accurate
Discover
TigerGraph
Wed 15 Jul 2026
TigerGraph 4.3: Built for Enterprise Security, Integration, and Scale
Discover
TigerGraph
Mon 13 Jul 2026
Why AI Is Redefining Enterprise Identity
Discover
Healthcare
Mon 29 Jun 2026
Healthcare Graph Database: How Graph Powers Cost Control, Fraud Detection, and Referral Intelligence
Discover
Risk and Fraud Analytics
Mon 29 Jun 2026
Graph Database for Risk and Fraud Analytics: Why Unified Fraud Detection Beats Siloed Systems
Discover
Graph Databases
Mon 29 Jun 2026
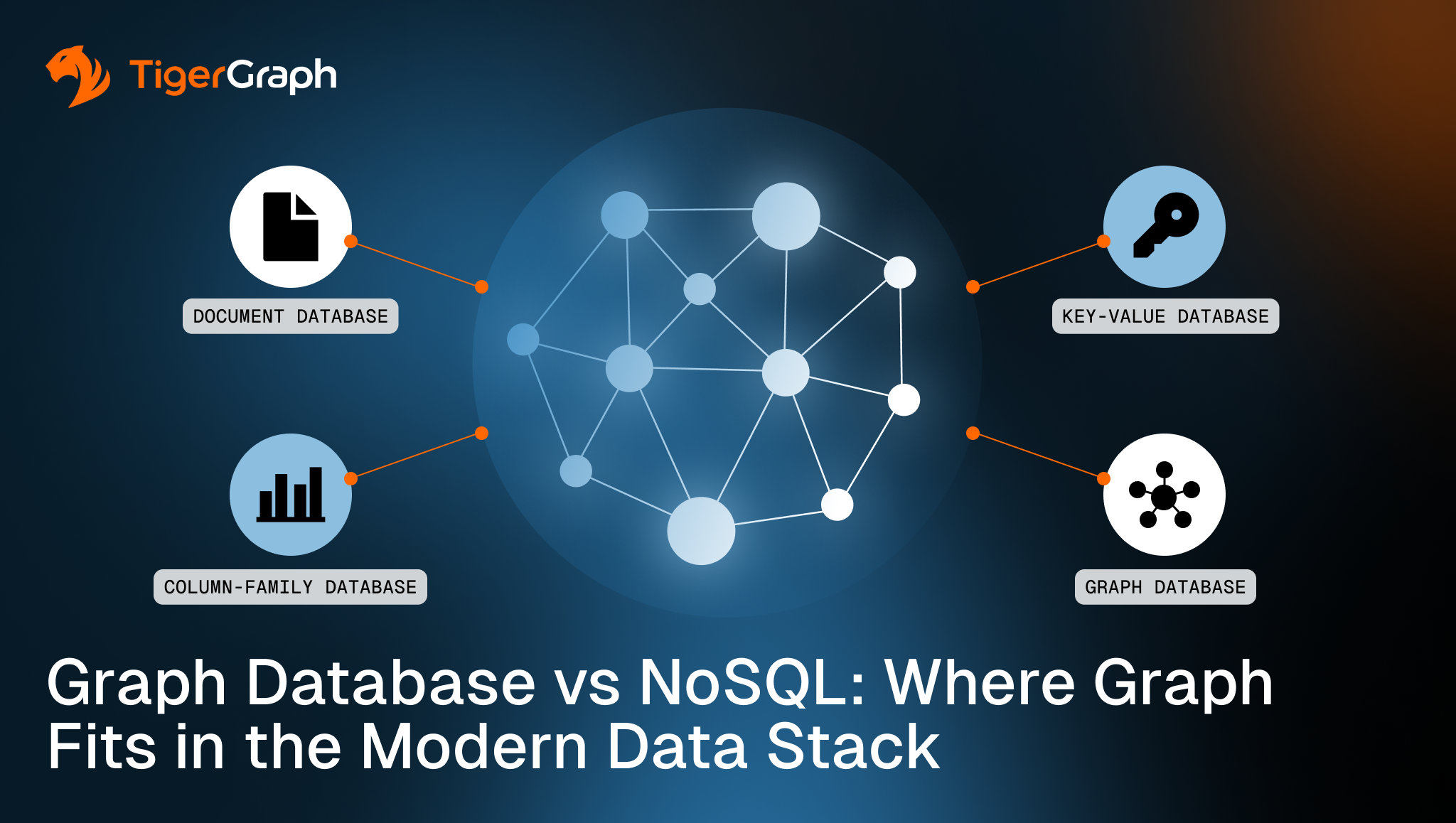
Graph Database vs NoSQL: Where Graph Fits in the Modern Data Stack
Discover
Show More