
Winners For Partner Innovation
Second Place – Knowledge Keeper
$6,000 for Charity of Choice
Summary
Learning is a lifelong process in the age of the internet. Today the problem is the abundance of resources in various forms (video, text, images) on a topic. Often you don’t know how useful a resource would be in terms of your prior knowledge and what you aim to learn from it. A normal search engine would provide generic resources (introductory and advanced) without considering your level of skillset. Another aspect is the pain in knowledge-keeping, storing, and sharing various resources. How can we make this time-consuming process more efficient/better?
The problems can be described in the following points –
- The abundance of resources on any topic
- Where to read/watch from next to fulfill your criteria of learning?
- Current search engines do not take your prior knowledge/ skill level into consideration while recommending resources to learn from
- How can we efficiently manage the things we learn? How can bookmarking be made more efficient?
- How can linked and domain knowledge data help us?
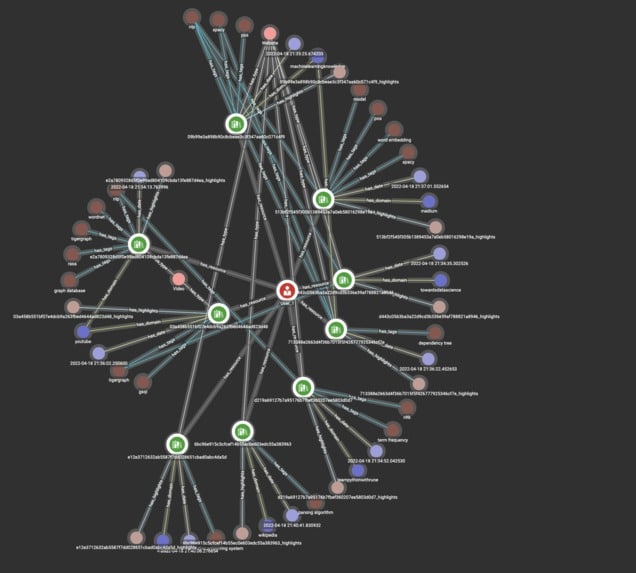
Our solution builds a learning journey over a lifetime. Any user can add to their own journey, share the journey and see other people’s journeys.
- Using our browser extension the user can easily add resources to track their learning journey.
- User can discover resources with similar tags and concepts.
- User can query over their own learning graph to revisit similar URLs saved.
- An automated graph generation is generated through which the user doesn’t have to manually attach the nodes.
Our solution is divided into the following parts –
- Browser extension by which users can add any URL to their own learning journey. They can save notes, highlights, tag the links
- Through NLP we discover similarities which help us to discover new relations and insights. We discover resources that share the same tag and which concepts.
- In the backend, there is a User-specific learning graph being formed in an automated manner. Nodes are URL’s, Date, tags, highlights, notes, type of resource
- Graph Backend/Database(Tigergraph) that help us to find relations and build a graph structure Get insights about your collected resources. Which resources are related to each other and in which way they are connected to each other?
- Our automated graph generation process takes the previously formed graph into consideration and finds out the correct node to attach to by similarity algorithms (We have this module ready, and need to query to GSQL to embed it into the pipeline)


