Contextual Entity Resolution in Banking – Beyond Just Matching
Every major bank faces one deceptively simple question: Who are we really dealing with? It’s a question that runs through every process in modern banking, from onboarding to fraud detection to AML/KYC compliance—all of which hinge on identity resolution in banking.
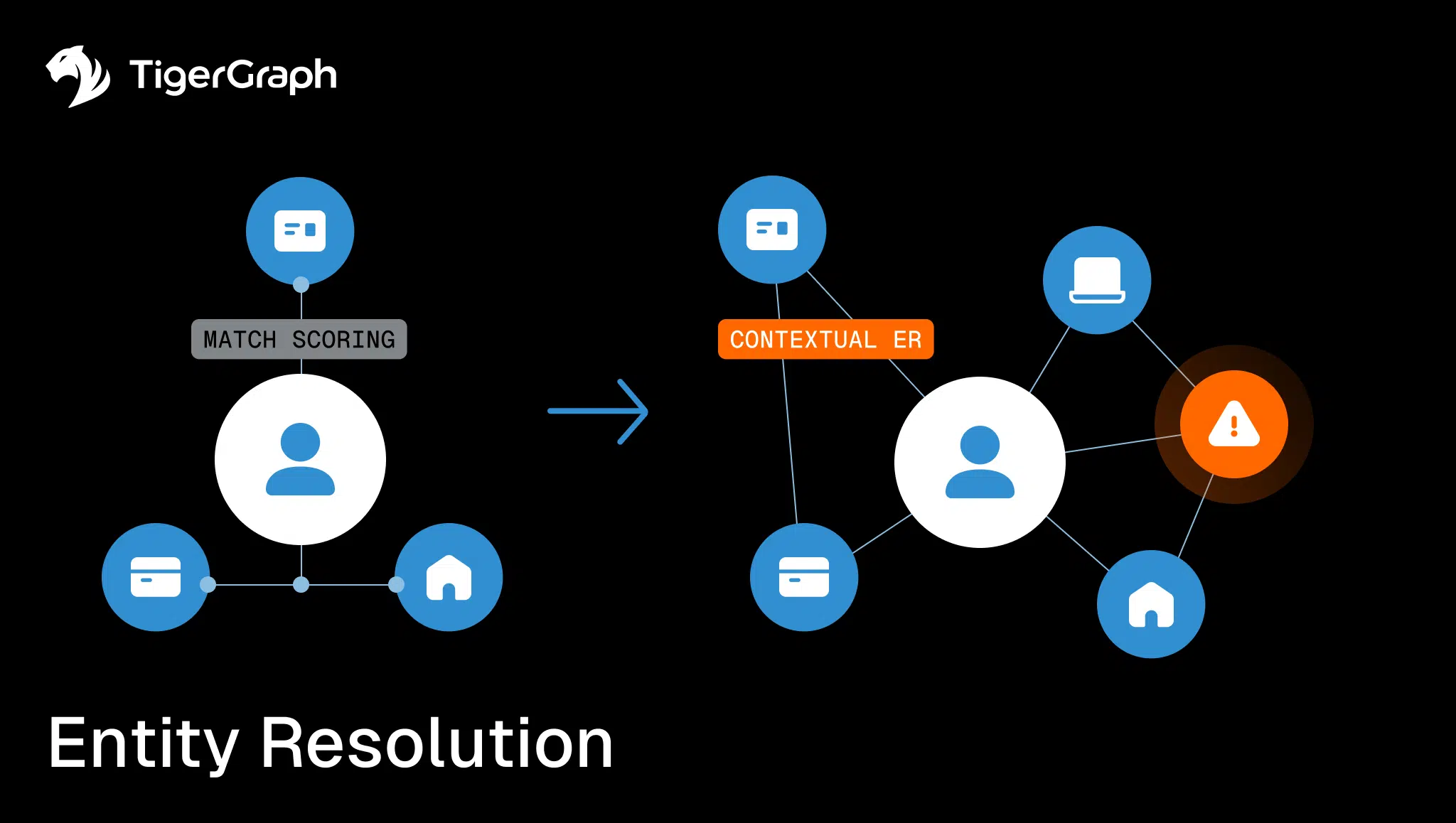
Most institutions rely on match scoring, with similarity checks, substitution rules like ‘Blvd for Boulevard,’ and weighted factors across attributes like names, DOB, and addresses.
This approach is valuable for cleaning up typos and duplicates, and most banks already do it well. However, it still treats records in isolation, missing the deeper relational context that exposes fraud and enables true compliance. This is why forward-looking banks are turning to identity resolution with context—a shift that captures relationships, not just records.
Contextual Entity Resolution (ER) goes beyond matching records. It improves accuracy by consolidating duplicates, but its greater value comes from revealing the relationships and behaviors connected to each identity. By framing entity resolution as both precise matching and connected context, banks can address compliance requirements and uncover fraud networks that would otherwise remain hidden.
Fraudsters exploit gaps, making synthetic identities look clean on paper and mule accounts mimic legitimate customers. Without context, banks over-flag legitimate activity while missing sophisticated fraud.
As a result, leaders are moving from “matching” to “connecting,” and from static strings to dynamic graph-powered entity resolution that exposes relationships, lineage, and behavior across the enterprise. And because contextual ER considers both identities and their networks of connections, it naturally extends into fraud detection and AML compliance.
What Match Scoring Delivers (and Where It Stops)
Traditional match scoring provides useful hygiene:
- Similarity scoring: catches typos (“Jon” vs. “John”).
- Substitution scoring: recognizes equivalents (“Mumbai” vs. “Bombay”).
- Weighted scoring: aggregates across fields (name, DOB, phone).
Match scoring is necessary, but not sufficient. Regulators now expect a shift from field-level similarity to contextual identity resolution that shows why records belong together.
But its limitations are clear. The most damaging is that records are treated in isolation, which makes it easy for fraudsters to spread attributes across synthetic identities. These gaps blind banks to collusion and hidden risk. False positives and scalability challenges add cost and complexity, but the central issue is lack of context. Taken alone, match scoring’s limitations leave institutions exposed.
This is where contextual entity resolution comes in.Traditional ER asks a narrow question: “Are these two records the same person?” Contextual ER asks the broader question: “Who and what is this person connected to?” That expanded view captures relationships and behaviors that record matching alone cannot. The result is more accurate resolution, greater scalability, and insights that compliance and fraud teams can act on with confidence.
Why Graph-Powered Entity Resolution Changes the Game
A graph database entity resolution approach shifts the model from comparing fields to mapping relationships. Instead of “Are these two strings close enough?” the question becomes: “How are these entities connected?”
Contextual ER delivers three advantages that legacy scoring cannot. The most critical is compliance lineage: when regulators ask why two records were merged, a graph shows the complete path, including devices, addresses, ownership—that supports the decision. In addition, it consolidates variations of the same customer into one accurate profile, and it exposes fraud networks that converge on shared infrastructure such as IP addresses or merchants.
Contextual Identity Resolution: Practical Benefits
Contextual ER delivers two levels of benefit. First, it makes identity resolution more accurate: duplicate profiles collapse into one true record, false positives decrease so investigators can focus on real risk, and audit-ready transparency provides path-level lineage regulators require.
Second, it strengthens fraud detection by mapping hidden relationships that traditional systems overlook. A graph framework shows when a party is connected to flagged entities or suspicious behaviors, while shared devices, merchants, and addresses expose coordinated fraud networks instead of isolated anomalies.
Match scoring vs. contextual entity resolution
| Dimension | Match scoring systems | Contextual entity resolution with graph |
| Context | Field-by-field strings | Multi-hop relationships & lineage |
| Accuracy | Limited by variation | Contextual ER improves match accuracy |
| Fraud detection | Limited without relationships | Contextual ER exposes fraud networks |
| Auditability | Scores only | Explainable paths with evidence |
| Scalability | Breaks at scale | Sub-sec across millions of events/day |
Real-World Impact in Banking of Entity Resolution
Contextual ER delivers impact by linking identities to their broader networks. It reveals the real parties behind synthetic identities and mule accounts, and shows how customers, devices, and merchants are connected. This broader context strengthens fraud detection, AML, and KYC alike.
In practice, contextual ER often appears in fraud or compliance use cases, where context analysis strengthens decision-making even if the core matching is handled elsewhere.
- Nubank: Faced 9,000+ fraud reports each month and $1.8M in monthly scam losses. Its models had recall rates as low as 28%, allowing synthetic identities and mule accounts to pass through. By integrating graph features such as PageRank fraud detection, community detection, and device proximity, Nubank significantly boosted recall, cut false positives, and prevented millions in monthly scam losses. This improved customer protection without requiring additional headcount.
- JPMC: Processes 50M+ transactions per day across a 30TB dataset. Previously, siloed systems flagged activity but missed cross-domain connections. With graph-powered context analysis, JPMC now generates 30+ graph-based fraud features (e.g., shortest paths to high-risk entities, device reuse, ownership overlaps). The result: fewer false positives, higher fraud detection accuracy, and $50M in annual savings—all while protecting 60M households.
Identity resolution in banking delivers its full potential when powered by contextual graph intelligence.
Recommendations for Executives
An investment in contextual entity resolution delivers measurable compliance, fraud reduction, and ROI. But in most banks, ER, AML, and fraud detection sit under separate teams. To make these recommendations actionable, we preface them by function:
- ER: Are we relying only on scoring tables?
Traditional match scoring systems, which rely on similarity, substitution, and weighted attributes, help improve data quality but overlook the deeper relational context that reveals collusion and fraud. Ask whether your vendors are providing dynamic identity resolution with behavioral linking, or just extending legacy scoring methods. - Fraud detection: Can our current tools scale with fraud and regulation?
Fraudsters exploit gaps across billions of fast-moving transactions, while regulators now expect lineage that spans silos. Without a graph database entity resolution platform that can handle millions of daily events, compliance teams will drown in false positives and miss critical connections. - AML/Compliance: Where is the ROI?
Entity resolution in banking should deliver measurable business outcomes. Leading banks using graph-powered entity resolution report double-digit improvements in detection accuracy, faster investigations, and hundreds of millions in fraud savings annually. If your current platform isn’t producing similar results, it’s time to reassess.
Contextual ER is not just “clean-up.” It is a foundation that strengthens fraud detection and compliance alike. By clarifying benefits for each function, leaders can pursue improvements in their own domains while also laying the groundwork for cross-silo collaboration.
Why TigerGraph Leads in Graph-Powered Identity Resolution
Most banks already run pilots that show graphs can unify customer records. The challenge is making those pilots production-ready at scale. TigerGraph was built for this reality, delivering speed, scale, explainability, and ML integration in ways that other platforms struggle to match:
Performance at enterprise scale: TigerGraph ingests and processes millions of daily events for Tier 1 banks while still responding in 10s of milliseconds on targeted queries. That means fraud detection, KYC onboarding checks, and AML screening can run in real time—even as payments and customer interactions stream in continuously. Unlike table joins or brute-force match scoring, graph queries filter efficiently across billions of relationships, surfacing the strongest matches in milliseconds.
High concurrency for live workloads: In banking, hundreds of analysts, data scientists, and automated systems need to query the same identity graph at once. TigerGraph supports thousands of simultaneous fraud and KYC queries without bottlenecks, ensuring no team is forced to wait for insights. This level of concurrency is what separates research projects from enterprise-ready deployments.
Graph-powered feature factory for ML: TigerGraph doesn’t just unify identities—it continuously generates advanced features like centrality measures of key entities, fan-in/fan-out patterns, and community memberships. These feed directly into AML and fraud models, improving precision and recall. For example, PageRank-derived influence scores can flag mule hubs before transactions settle, while proximity features reveal when a “new” account is only two hops from a known fraud ring.
Explainability and audit readiness: Regulators no longer accept black-box scoring. TigerGraph provides path-level lineage showing who was connected, when, and how. Investigators can export full evidence trails—shared devices, ownership chains, IP reuse—that explain exactly why a customer was flagged. This satisfies AML/KYC compliance requirements and builds trust with auditors and boards.
The result is that graph-powered fraud prevention and behavioral identity resolution are not just theoretical. TigerGraph makes them operational, turning what used to be fragile pilots into always-on infrastructure.
For banks under pressure from both regulators and fraudsters, that’s the difference between “experimenting with graphs” and using graph as a core identity resolution strategy that reduces losses, speeds onboarding, and delivers measurable ROI.
Match scoring still plays a role in cleaning and standardizing records, but it must be augmented with relationships and behavioral linking. TigerGraph provides that added context, turning partial matches into complete, regulator-ready identity resolution.
Entity Resolution Conclusion
Match scoring is a start, but it’s not enough for fraud detection in banking, AML fraud detection, or customer identity resolution. Only graph-powered entity resolution provides the context that regulators demand, fraudsters can’t evade, and customers expect.
With TigerGraph, banks get the speed, scale, and transparency to unify identity, stop fraud, and satisfy compliance. The result: fewer false positives, faster investigations, and measurable ROI.
Cleaner data. Stronger compliance. Lower risk. Reach out today to learn more and explore TigerGraph Cloud to experience graph-powered identity resolution in action.
