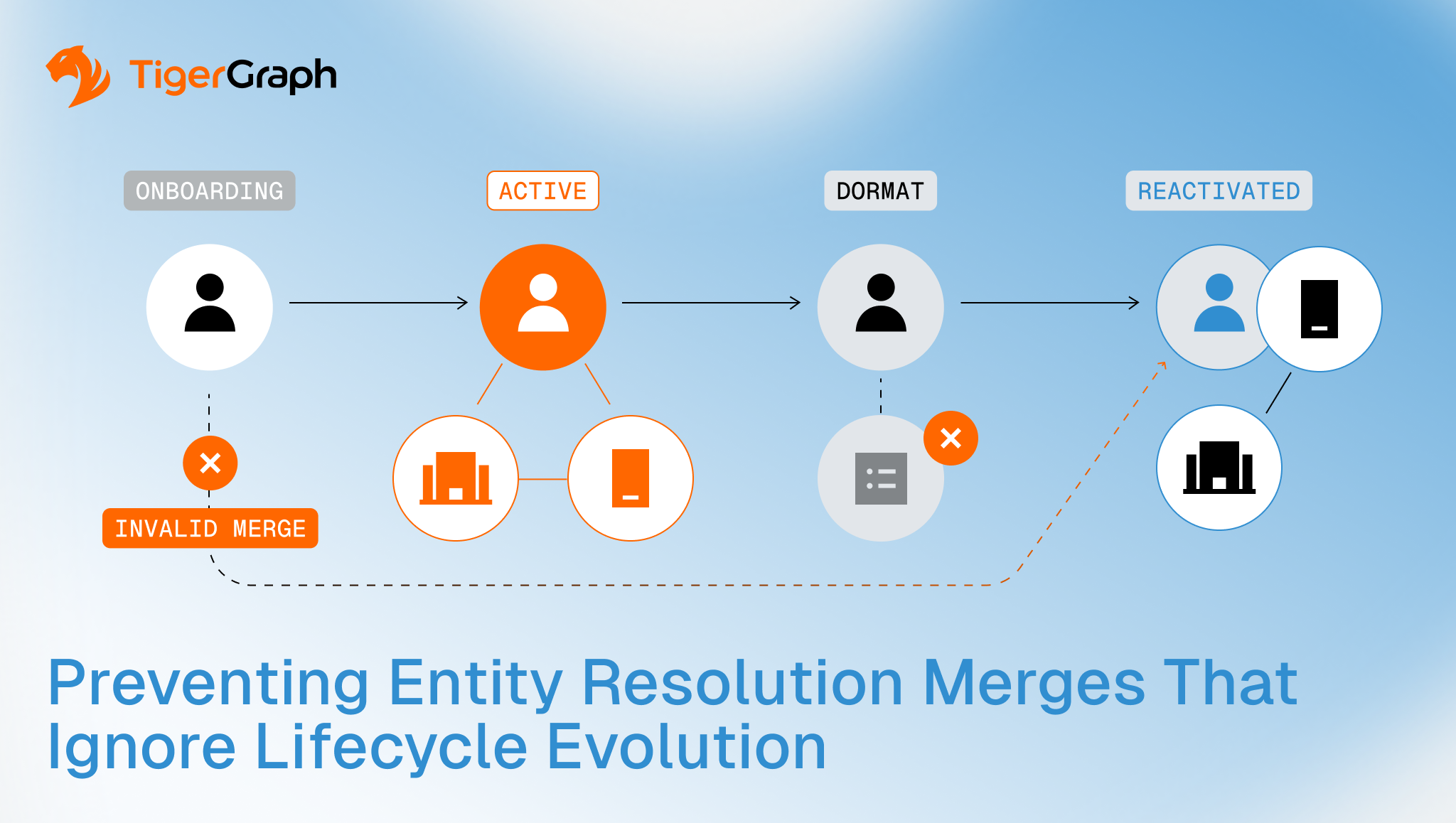
Preventing Entity Resolution Merges That Ignore Lifecycle Evolution
It feels logical to treat entity resolution as a convergence problem. As records arrive over time and attributes accumulate, confidence increases. Eventually, everything that belongs together is merged into a single, stable entity.
But that model logic breaks down because identity does not stand still.
The variables are endless. People change addresses, devices and contact details. Businesses restructure, spin off subsidiaries, dissolve entities and reconstitute under new ownership. Accounts open, close and go dormant. Relationships expire even if records persist.
When entity resolution ignores lifecycle, it begins merging records that should no longer belong together. The result is an entity view that looks comprehensive but no longer represents a single, coherent subject.
This is how lifecycle-blind merges quietly degrade identity truth, and we are going to explore how to prevent them.
Key takeaways
- Entities evolve over time, but resolution logic often treats identity as static.
• Merges that ignore lifecycle stage can combine records that no longer belong together.
• Stale, incompatible or expired relationships distort resolved entity views.
• Graph-based workflows support lifecycle-aware resolution by preserving time, role,and relationship context.
To see why this happens so consistently, it helps to look at how most resolution logic treats time.
Why Lifecycle Matters in Entity Resolution?
Entity resolution answers a practical question. Which records represent the same real-world entity right now? It’s a question that changes as entities evolve.
Most resolution pipelines are optimized to detect similarity. If names align, addresses overlap, and identifiers match, then similarity increases, and records are merged.
What similarity alone does not capture, though, is when those attributes were valid and whether they still apply.
A record that was correct five years ago may no longer describe the current entity. A relationship that once implied control may have expired. An identifier that once anchored resolution may have rotated.
When lifecycle is ignored, resolution logic assumes continuity where none exists, and these assumptions surface in predictable, repeatable ways.
How Lifecycle-Blind Merges Show Up in Practice
Programs tend to encounter lifecycle failures in a few recurring patterns.
Merging records from incompatible lifecycle stages
Onboarding records merge with post-closure activity, dormant entities merge with active ones, and historical profiles collapse into current views, regardless of timing.
Expired relationships treated as active
Ownership, control or operational relationships persist in the resolved entity even after they are no longer valid. Exposure logic continues to rely on links that should have aged out.
Identity drift masked by aggregation
Attributes change gradually, as devices rotate and behaviors shift. Instead of triggering reassessment, resolution absorbs the changes into a growing entity cluster that no longer reflects a single state.
Reactivation without separation
Entities that go dormant and later reappear are treated as continuous, even when the material context has changed. Resolution assumes everything stays the same rather than reevaluating relevance.
In each case, the issue is that time is not being evaluated as part of the merge validity process.
These merge patterns do not stay confined to resolution. They ripple into every workflow that depends on the resolved entity.
Why Lifecycle-blind Resolution Creates Downstream Risk?
When a resolved entity is treated as fixed, teams assume the identity is settled, but behavior and context change over time. Detection models end up learning from a mix of old and current information and risk scores blend activity from different stages of an entity’s life. Investigators are then left trying to explain today’s behavior using attributes that may no longer apply.
When questions arise, explanations become fragile.
- Why are these records merged?
- Why does this relationship still matter?
- Why is this entity treated as continuous when the evidence changed?
The answers often depend on assumptions rather than reviewable evidence. This is how lifecycle failures turn into inconsistent outcomes instead of obvious data defects.
Addressing these downstream issues starts with rethinking what evidence resolution should consider.
What Lifecycle-aware Resolution Actually Requires?
Lifecycle-aware resolution does not require predicting intent or modeling behavior change. It requires treating time, role, and relationship validity as first-class evidence.
This means asking:
- Was this relationship valid at the same time as the evidence it supports?
- Does this attribute still describe the entity in its current stage?
- Should this link persist, weaken or expire as conditions change?
- Does this merge still make sense given what happened since it was created?
These questions cannot be answered solely from static similarity. This is where connected context becomes essential.
What Connected Analysis Adds
Connected analysis makes the lifecycle visible. Instead of evaluating records only at rest, teams can evaluate how relationships and attributes evolve over time within the network.
This supports several critical capabilities.
Temporal validation of links
Relationships can be assessed based on when they were active, not just whether they exist.
Detection of stale or incompatible connections
Traversal, or walking relationships step by step across connected entities, makes it possible to identify links that persist even though the underlying evidence has changed over time.
Separation of historical context from current identity
Historical relationships remain available for explanation without automatically influencing present-day resolution.
Reviewable merge decisions
When merges are questioned, teams can show not only what matched, but why it still matched given the entity’s evolution.
This preserves continuity without forcing permanence. Making lifecycle visible changes how teams review and correct decisions.
How this Improves Review, Quality Assurance, and Remediation
Lifecycle-aware resolution improves explainability.
Investigators can see when links were formed, how long they were valid and what evidence replaced them. QA teams can identify resolution failures tied to aging, drift or improper persistence rather than logic defects.
Remediation becomes targeted. Instead of splitting entire entities, teams can retire specific links, reclassify lifecycle stages or adjust merge rules where timing invalidates assumptions.
Most importantly, outcomes become easier to defend because identity decisions reflect how entities actually change over time.
Supporting this level of lifecycle-aware analysis requires more than adding timestamped records to the workflow.
How TigerGraph Fits the Workflow
The operational challenge is evaluating identity structure as it evolves. TigerGraph supports lifecycle-aware resolution by enabling:
- Time-aware relationship modeling
• Traversal across relationships with temporal constraints
• Path-level evidence showing when and why links are applied
• Consistent queries that distinguish historical context from current structure
The system provides the connected context needed to apply program-defined rules consistently and transparently. For most programs, adopting lifecycle awareness starts with a few concrete governance changes.
Practical Steps for Lifecycle-aware Resolution
Programs seeking to reduce lifecycle-driven resolution failures often start with a few actions.
- Define which relationships expire, weaken or require revalidation over time
• Separate historical context from active identity structure
• Review merges that span incompatible lifecycle stages
• Treat identity change as a trigger for reassessment, not automatic aggregation
Lifecycle awareness works best when it is embedded into resolution governance, not handled as an exception.
Conclusion
Entity resolution fails quietly when time is ignored. Identities do not break all at once; they evolve. Lifecycle-aware resolution places historical context in the right frame.
By evaluating whether links and merges still make sense given when the evidence occurred, teams can prevent stale context from distorting identity and undermining confidence in outcomes.
A single customer view is not defined once. It has to be maintained as the entity changes.
If your teams are struggling with merges that no longer reflect how entities actually change over time, contact TigerGraph to see how connected analysis helps keep identity views accurate and reviewable as conditions evolve.
Frequently Asked Questions
1. What is Lifecycle-aware Entity resolution in Fraud and AML Systems?
Lifecycle-aware entity resolution is the practice of evaluating identity records based not only on attribute similarity but also on when relationships, identifiers, and attributes were valid. In fraud, AML, and KYC systems, identities evolve over time as customers change addresses, devices, ownership structures, or account status. Lifecycle-aware resolution ensures that records are merged only when they represent the same entity during the same time period, preventing outdated relationships from distorting the current identity view.
2. Why can Traditional Entity Resolution Create Inaccurate Identity Views in Financial Systems?
Traditional entity resolution focuses on matching similar attributes such as names, addresses, or identifiers. However, it often ignores when those attributes were valid. In financial systems, identities frequently change as accounts close, businesses restructure, or devices rotate. When resolution logic treats these attributes as permanent, it can merge records that belong to different lifecycle stages, creating identity profiles that combine outdated and current information.
3. How do Lifecycle-blind Identity Merges Affect Fraud and AML Investigations?
Lifecycle-blind merges can distort investigations by combining historical and current identity evidence into a single profile. Fraud and AML investigators may see relationships that are no longer valid, such as expired ownership links or outdated contact information. This can lead to incorrect risk assessments, confusing investigation paths, and inconsistent case decisions because analysts cannot clearly distinguish between historical context and current activity.
4. How can Graph Analytics Help Manage Identity Changes Over Time?
Graph analytics helps manage identity changes by modeling entities, attributes, and relationships as a connected network that includes temporal context. Investigators and data teams can traverse identity relationships and evaluate when those links were active. This allows organizations to separate historical identity evidence from current relationships, detect stale connections, and ensure that entity resolution decisions reflect how identities evolve over time.
5. Why is Time-aware Identity Modeling Important for KYC, Fraud, and AML Programs?
Time-aware identity modeling is critical for KYC, fraud, and AML programs because regulatory decisions and risk assessments depend on accurate identity context at a specific point in time. Without lifecycle awareness, identity resolution may rely on outdated relationships or attributes. Graph-based identity models allow institutions to evaluate when connections existed, helping investigators and compliance teams make defensible decisions based on current and historically valid evidence.
