Think You Understand Machine Learning? Try it with Graphs
Most enterprise teams believe they are already doing machine learning well. They have models, feature pipelines, training data, and evaluation metrics. But there is a harder question. Are those models learning from relationships or just rows?
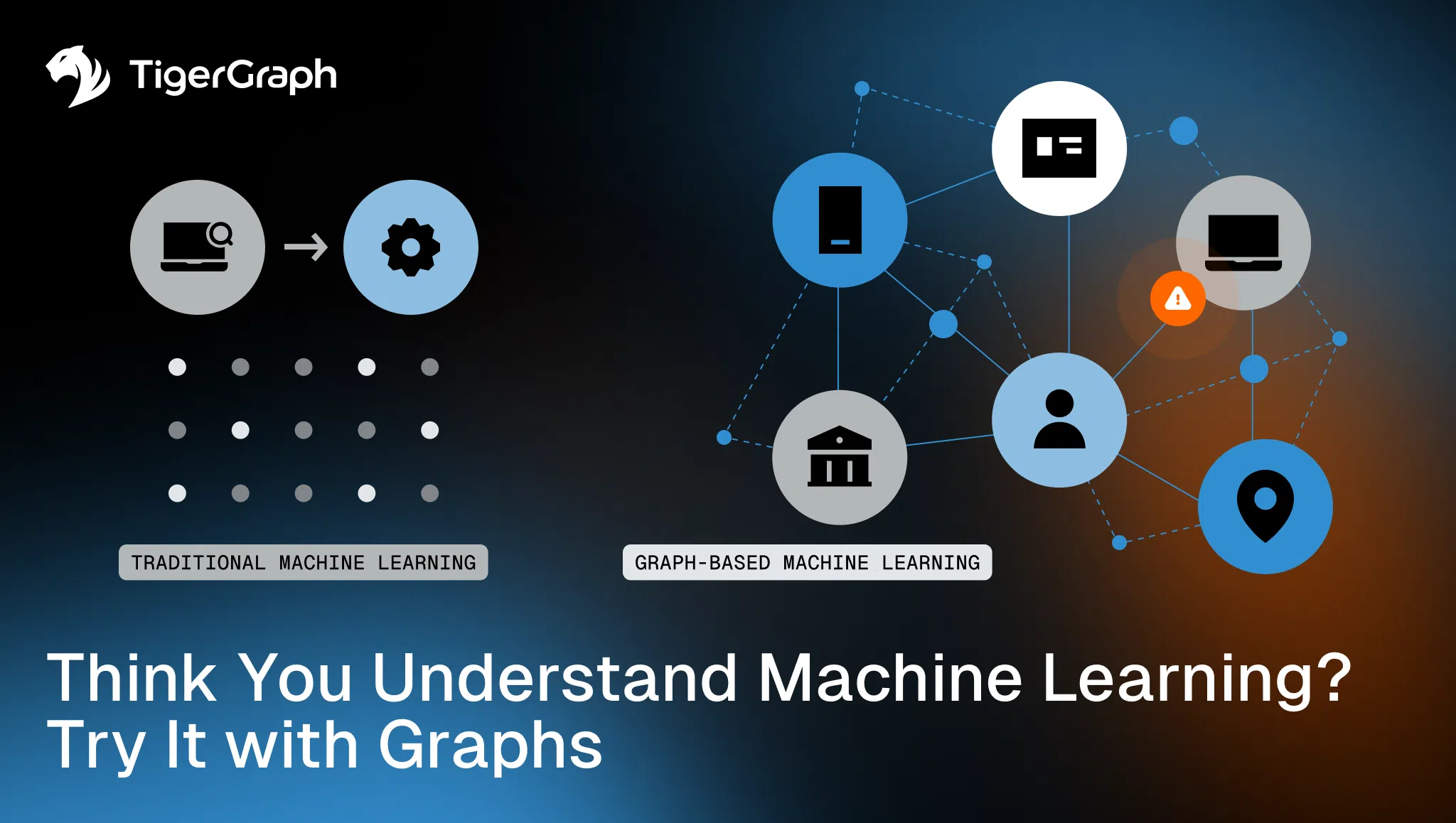
Most machine learning pipelines are built on tabular assumptions, with each record treated as independent. Features are engineered from attributes, and models are trained to predict outcomes based on isolated rows. That framework works for many problems, but it breaks down when outcomes depend on relationships.
- Fraud spreads across connected accounts.
- Risk propagates through supply chains.
- Recommendations emerge from shared behavior across users.
- Influence moves through investor and ownership networks.
When structure matters, independence becomes an illusion.
Graph-enhanced machine learning introduces relational context directly into predictive models. Instead of learning only from attributes, models learn from how entities connect. That shift changes what models are able to see.
Key Takeaways
- Traditional machine learning treats entities as independent observations.
- Many enterprise problems involve relational dependencies across networks.
- Graph feature engineering introduces network-aware signals into predictive models.
- Graph embeddings capture structural similarity across entities.
- Graph neural networks incorporate neighborhood context during model training.
- Identity resolution, fraud detection, and risk analysis improve when models incorporate relationships.
The Limits of Flat Feature Engineering
Traditional machine learning workflows typically follow a familiar pattern.
- Extract attribute
- Engineer features
- Train a model
- Score predictions
This works well when entities behave independently, but many real systems do not.
- Fraud detection involves coordinated activity across accounts.
- Customer behavior emerges through shared devices and communities.
- Supply chain risk spreads through connected suppliers and logistics partners.
A transaction does not exist in isolation and an account’s risk depends on other accounts it touches. If feature engineering ignores relational context, predictive models miss structural signals. Accuracy may still appear acceptable, but structural intelligence remains absent.
This is where graph feature engineering comes in.
Graph Feature Engineering
Graph analysis changes how features are constructed. Instead of describing entities solely by attributes, graph methods compute metrics that capture their positions within a network. Examples include:
- Degree, measuring connectivity volume
- PageRank, estimating influence within a network
- Betweenness centrality, identifying nodes that sit on important paths
- Proximity metrics, measuring distance to known high-risk entities
These features quantify structural roles. An entity’s position inside a network becomes predictive signal.
For example, two accounts may share identical transaction attributes. One may sit within a dense cluster of fraudulent activity while the other does not. Flat features treat them as identical but graph features reveal the difference.
Even with these improvements, graph feature engineering still relies on manually defined metrics. Embeddings take the next step by allowing models to learn structural representations directly from the network.
Embeddings: Learning Structural Similarity
Graph embeddings extend this idea. Instead of manually crafting every structural metric, embeddings encode nodes into vector representations based on their neighborhood.
Entities that occupy similar structural positions map to nearby points in vector space. Two entities may appear unrelated when viewed through attributes alone, but if they participate in similar connection patterns, embeddings reveal the similarity.
This allows models to learn structural roles automatically rather than relying entirely on handcrafted features. Similarity becomes relational rather than purely attribute-based.
Embeddings capture structural similarity. Graph neural networks extend this concept by allowing models to learn directly from the flow of information across the network.
Graph Neural Networks
Graph neural networks take relational learning further.
Traditional neural networks evaluate each training example independently. Graph neural networks aggregate information from neighboring nodes during training. Each node’s representation evolves based on the surrounding structure.
Instead of analyzing isolated records, the model learns patterns across the network itself.
In one fraud detection experiment, graph-enhanced models outperformed traditional approaches such as gradient boosting because they incorporated relational context directly into prediction. The model is no longer asking whether a transaction appears unusual. It evaluates how that transaction fits within a broader network of activity.
When relational context becomes part of model training, predictive systems begin to capture patterns that flat models cannot represent.
Why Structure Changes Outcomes
When predictive models incorporate relationships, they detect signals that flat models cannot.
Examples include:
- Circular transaction patterns
- Shared device clusters
- Communities of coordinated fraud activity
- Central orchestrator accounts within networks
These signals are not visible from isolated records. They emerge from structure. And the same principle applies across multiple domains:
- Risk scoring across financial networks
- Recommendation systems based on shared behavior
- Supply chain disruption analysis
- Sanctions exposure monitoring
In these environments, relationships drive outcomes and predictive models must reflect that structure.
Entity resolution illustrates how structural intelligence changes outcomes in practice.
Entity Resolution Illustrates Identity as a Network
Entity resolution provides another example of why relational context matters.
At first glance, identity resolution appears straightforward. Systems attempt to match records based on attributes such as name, address, email, or phone number. However, identity data quickly becomes ambiguous.
- Names change.
- Addresses vary.
- Companies restructure.
- Individuals use multiple accounts or devices.
- Fraudsters deliberately manipulate attributes.
Traditional resolution systems rely on similarity thresholds. If attributes match above a certain score, records merge. If they fall below the threshold, they remain separate. This approach is fragile. Identity is not simply an attribute, it is a network.
Graph-based entity resolution evaluates relationships between records rather than relying only on string similarity. Shared neighbors, transaction patterns, device connections, and behavioral signals provide stronger evidence of identity than isolated attributes.
Structural validation reduces both false merges and missed matches. Accurate identity resolution strengthens downstream analytics across fraud detection, compliance monitoring, and customer intelligence.
Entity resolution is only one example of how relational intelligence improves machine learning systems. The same structural context can strengthen predictive models across a wide range of enterprise applications.
Introducing Relational Intelligence to ML Programs
Many organizations already have strong machine learning programs. The next step is introducing relational intelligence into those models.
Graph technologies allow teams to incorporate structural context alongside traditional features, improving predictive accuracy in domains where relationships drive outcomes.
Contact or connect with TigerGraph to learn how graph-enhanced machine learning can strengthen fraud detection, identity resolution, and risk analytics across connected data environments.
Frequently Asked Questions
1. What is Graph-Enhanced Machine Learning and How Does it Improve Model Accuracy?
Graph-enhanced machine learning incorporates relationships between entities into model training, improving accuracy by capturing patterns that isolated data cannot reveal.
2. Why do Traditional Machine Learning Models Miss Critical Patterns in Connected Data?
Traditional models miss critical patterns because they treat data as independent rows, ignoring the relationships that drive outcomes in real-world systems.
3. How do Graph-Based Features Improve Predictive Performance in Fraud and Risk Models?
Graph-based features improve performance by capturing connectivity, influence, and proximity—revealing hidden patterns like coordinated activity and shared infrastructure.
4. What is The Role Of Relational Data in Modern Machine Learning Systems?
Relational data provides context about how entities interact, enabling models to understand structure, dependencies, and network-driven behavior.
5. How can Organizations Integrate Graph Intelligence into Existing Machine Learning Pipelines?
Organizations can integrate graph intelligence by enriching features with network metrics, using graph embeddings, and incorporating relational context into model training.
