Why Payment Fraud Is Now a Multi-Model Architecture Problem
Fraud detection has outgrown single-model thinking.
For years, institutions focused on improving individual models with better algorithms, more data and higher accuracy. That approach delivered incremental gains, but fraud evolved just as quickly. It now spreads across timelines, devices, merchants and coordinated networks, so optimizing one layer in isolation no longer moves the needle.
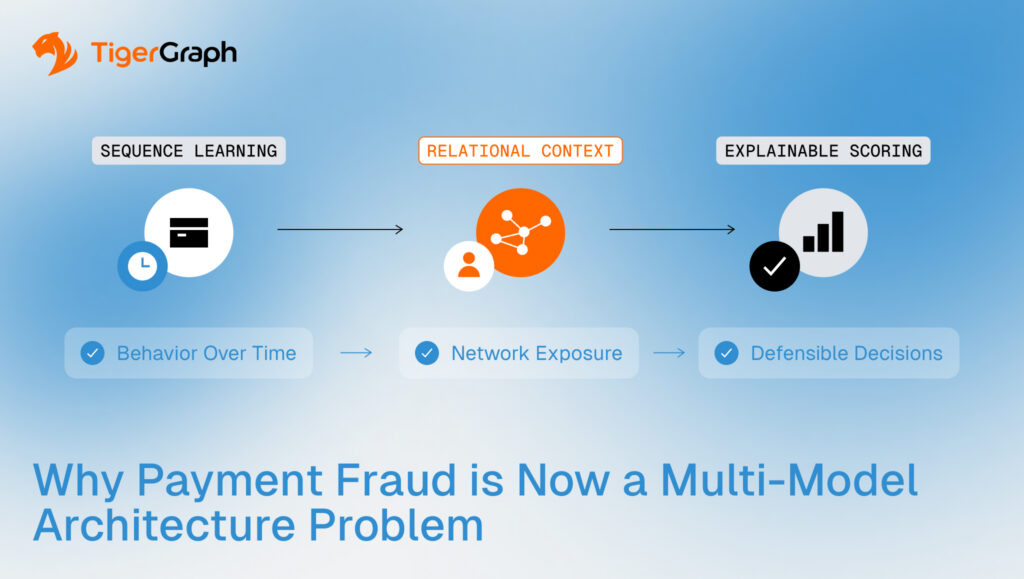
What matters now is how sequence learning, relational context and explainable scoring operate together inside a production system.
Across payments and financial services, major infrastructure providers are seeing growing demand for integrated architectures that combine transformer models for sequence learning, graph neural networks for relational context, and explainable scoring layers such as XGBoost. The conversation has shifted away from institutions debating whether these models work to them now asking how to deploy and maintain these models reliably, in real payment environments.
Model innovation is accelerating and system orchestration is the constraint.
Fraud Now Has Three Demands
Modern fraud detection must address three problems simultaneously: behavioral change over time, relational exposure across connected entities, and decisions that can be explained and defended.
No single modeling technique handles all three well. That is why layered architectures are emerging. Each model type handles a different dimension of risk. The advantage comes from how they operate together inside a single production architecture.
To see how that works, start with behavior.
Step One: Behavior Over Time
Payments are inherently sequential. A customer’s activity forms a timeline and patterns develop across hundreds of transactions.
Transformer models are designed to learn from sequences. In fraud detection, they analyze the order and timing of transactions and convert that history into a compact numerical representation, often called an embedding. That representation captures spending rhythm, merchant shifts, geographic changes and subtle anomalies.
Stripe has publicly reported improving fraud detection accuracy from roughly 57 percent to 95 percent after introducing payment transformers with sequential embeddings. That result reinforced what many in the industry were already seeing: transformers are becoming foundational models for payments.
But behavior alone does not reveal coordination, with fraud rarely remaining confined to a single account.
Step Two: Relationships Across the Network
Fraud rarely lives inside a single transaction stream. It spreads through shared devices, synthetic identities, mule accounts, merchant clusters and intermediary routing paths. These signals exist in relationships.
Traditional machine learning models typically work with tabular data. They may include graph-derived features, but the graph itself is not part of the learning process. The relational signal is reduced before training begins.
A graph neural network works differently.
Instead of discarding the graph after preprocessing, a GNN incorporates neighbor information directly into the training process. During learning, the model evaluates each entity along with its connected neighbors. It aggregates contextual signals from those neighbors and iteratively adjusts its internal weights.
In simple terms, the model does not evaluate an account in isolation. It evaluates how that account behaves and how it is positioned within its network.
In a combined system, the transformer first summarizes how an account behaves over time. Then the graph neural network adds context by looking at how that account connects to others. The final result reflects both behavior and network exposure. This is where fraud detection becomes truly network-aware.
However, relational learning only works if the graph reflects reality. Payment ecosystems change continuously. Devices link to new accounts, merchants shift patterns and intermediary chains evolve. If the graph is stale, the contextual signal degrades.
Continuous graph synchronization is an architectural requirement in high-velocity payment environments.
Step Three: Decisions That Can Be Defended
Even the most advanced representations must produce decisions that risk teams can explain.
Fraud systems operate under regulatory scrutiny. A declined transaction must be justified and a blocked account must be defensible.
That is why many production architectures use XGBoost as the final scoring layer. While transformers and graph neural networks generate rich representations, XGBoost produces a structured, interpretable risk score. It creates separation between complex representation learning and operational decision-making.
Accuracy improves detection. Explainability determines whether the system can run in production.
The Real Challenge Is Integration
At a conceptual level, the layered model makes sense. In practice, building and maintaining it is difficult.
A production-ready architecture must coordinate real-time transaction ingestion, continuous graph updates, GPU-enabled training pipelines, embedding refresh cycles, low-latency inference and stable deployment infrastructure. And each component depends on the others.
Leading global financial institutions may have internal data science teams capable of assembling this stack. Many others do not want to engineer and maintain the entire pipeline themselves.
Demand is growing for systems that come ready to run. Banks do not want to stitch these components together themselves. They want architectures that reduce engineering burden while still improving accuracy, speed and cost efficiency.
Institutions are asking how to make these model layers work together reliably at scale.
From Architecture to Advantage
Fraud detection has entered a new phase, with a focus on architecture that can support sequence learning, relational context, and explainable decisioning together, at production scale.
Transformers detect behavioral shifts, graph neural networks uncover network exposure and XGBoost produces defensible risk scores. But those components only create advantage when they operate inside a synchronized, real-time graph foundation.
TigerGraph is built to support this architectural shift. Its high-performance graph infrastructure keeps relational data synchronized with live transactional flows, enabling GNN pipelines and multi-model architectures to operate with current, connected context in high-velocity environments.
If your fraud strategy is moving toward a multi-model architecture, the critical question is whether your underlying graph infrastructure can support it at scale. TigerGraph enables production-grade graph + AI fraud systems designed for real-time, network-aware detection. Contact our team to evaluate your architecture and explore a production-ready path forward.
Frequently Asked Questions
1. Why is Fraud Detection Shifting From Single-model Systems to Multi-model Architectures?
Modern fraud spans behavioral patterns, network relationships, and regulatory decision requirements. Single models struggle to capture all three dimensions effectively. Multi-model architectures combine sequence learning, relational context, and explainable scoring to deliver more accurate, production-ready fraud detection across complex payment ecosystems.
2. How do Multi-model Fraud Detection Systems Improve Detection Accuracy at Scale?
By integrating behavioral modeling, network analysis, and interpretable scoring layers, multi-model systems evaluate risk from multiple perspectives simultaneously. This reduces blind spots created by isolated modeling approaches and improves the ability to detect coordinated fraud, evolving attack strategies, and distributed risk signals across large transaction volumes.
3. What Infrastructure Challenges Must Organizations Address to Deploy Multi-model Fraud Detection?
Deploying multi-model architectures requires real-time data pipelines, continuously updated relationship data, scalable training environments, and low-latency inference systems. Without synchronized infrastructure, model performance degrades due to outdated context, delayed signals, or operational complexity that slows production deployment.
4. How Does Real-time Relational Context Improve Payment Fraud Detection Outcomes?
Fraud networks evolve rapidly across accounts, devices, and merchants. Real-time relational context ensures detection models evaluate entities based on current network exposure rather than historical snapshots. This enables earlier identification of coordinated fraud activity and more precise risk assessment in high-velocity payment environments.
5. What Role Does Explainable Scoring Play in Modern Fraud Detection Architectures?
Explainable scoring enables risk teams to justify automated decisions under regulatory scrutiny. By translating complex model outputs into interpretable risk scores, organizations can operationalize advanced detection techniques while maintaining transparency, auditability, and compliance with financial oversight requirements.
