





With the graph database market on the rise, it is important to understand the differentiators between each vendor. TigerGraph is the first and only native parallel graph with massively parallel processing, but does that translate into the fastest performance? We’re happy to report: yes.
With TigerGraph’s 2.2 release on the horizon, we are excited to share the findings of our reproducible benchmark report comparing several key graph database vendors: TigerGraph, Neo4j, Amazon Neptune, JanusGraph, and ArangoDB. Using the latest community or free editions of these graph platforms, we checked out the following characteristics
- Bulk loading speed
- Storage size of loaded data
- Graph traversal speed for 1, 2, 3, and 6 hops
- Query speed vs. cluster size

Summary
Picking a Test Machine
It’s tricky picking the right system configuration for your software test. To be really fair, you’d like to design a test that can be run on a wide range of different system configurations. Since we included Amazon Neptune in our report, our choice was narrowed. Neptune is offered in only 5 machine configurations. We selected their 2 beefiest, and then did our best to emulate that with conventional EC2 instances. Neo4j and Amazon Neptune are not available as distributed graphs, so we focused most of the tests on single-server configurations. The full details are in our Benchmark Report.
Test Results
- Graph traversal and query speed: For 2-hop path queries, TigerGraph is 40x to 337x faster than other graph databases.
- TigerGraph’s advantages increase as the number of hops increase.
- Distributed Graph performance: TigerGraph scales almost linearly with additional machines, achieving 6.7x speedup with 8 machines for the computationally intensive PageRank algorithm. Neo4j and Amazon Neptune don’t offer a distributed graph.
- Parallelism at work: TigerGraph loads data 1.8x to 58x faster than other graph databases.
- Compression: Other graph databases need 5x to 13x more disk space than TigerGraph to store the same data.
- Bulk Loading Speed
For each graph database, we selected the most favorable method for bulk loading of initial data to examine the loading time, loading speed, and storage size of loaded data sets. We used two data sets throughout our tests.
Bulk Loading Results
- TigerGraph’s online loading mode is 1.8x to 2.7x faster than Neo4j’s offline loading mode. Online means you can continue to run other graph operations while loading is in progress; offline means you can’t.
- TigerGraph loads the smaller dataset 12x to 31x faster than the other graph databases. It loads the larger dataset 18x to 58x faster.
What We Learned
Setting up benchmark tests for products with different APIs and different query languages is more than just plug-and-chug. You have to learn to use each product, and you’ll learn things about them along the way. We discovered that most of the other platforms required some data pre-processing or post-processing. Here are some of the things we learned:
- If you want decent query speed with Neo4j, you need to build an index, after you load the data, so we included the index-creation time in our accounting.
- Most of the platforms can read a simple CSV formatted file, but Amazon Neptune requires a custom format.
- JanusGraph ran into memory problems unless we chopped up the input files into smaller chunks and loaded them one at a time.
Storage Size of Loaded Data
The size of the loaded data is an important consideration for system cost and performance. All other things equal, a compactly stored database can store more data on a given machine and has faster access times because it gets more cache and page hits. TigerGraph automatically encodes and compresses data, reducing the raw data size to less than half its original size.
- TigerGraph reduced the input data size by 50% for Graph 500 dataset and by 61% for the Twitter dataset.
- The other graph databases demanded 5x to 13x more storage space than TigerGraph.
Graph Traversal Speed
There’s an unlimited number of queries you could run on a graph, and each is going to test the characteristics of the platform in different ways. Instead of having a really big and diverse set of queries, we took a different approach: example some fundamentals of graph querying:
- Traversing ALL the edges with a given hop radius of a starting point
- Perform classic graph algorithms, which includes full graph traversal, computation on every node, and assessment of distributed graph performance.
K-hop-path neighbor count query
The k-hop-path neighbor count query asks for the total count of the vertices which have a k-length path from a seed vertex. For each dataset we measure the query response time for the following queries:
- Count all 1-hop path and 2-hop path endpoint vertices, using 300 fixed random seeds. Set a response time limit of 3 minutes.
- Count all 3-hop-path and 6-hop path endpoint vertices for 10 fixed random seeds. Set a response time limit of 2.5 hours.
Here are the results:
- TigerGraph is 2x to 69x faster on the 1-hop path query.
- Starting with 2 hops, other graph databases sometimes could not finish a test due to a timeout failure or running out of memory. The problems got worse as the hops increased.
- Looking only at the trials where a database was fast enough to complete the test, TigerGraph is 40x to 337x faster at 2 hops and 125x to over 4000x times faster at
- Only TigerGraph could complete the 6-hop path query (in 1.8 secs on the small graph and 63 secs on the large graph).
Weakly Connected Component and PageRank Queries
A weakly connected component (WCC) is the maximal set of vertices and their connecting edges which can reach one another, if the direction of directed edges is ignored. The WCC query finds and labels all the WCCs in a graph.
PageRank is an iterative algorithm which traverses every edge during each iteration and computes a score for each vertex. After several iterations, the scores will converge to steady state values. For our experiment, we run 10 iterations.
For TigerGraph, we implemented each algorithm in the GSQL language.
For Amazon Neptune, we did not find any way to run algorithmic queries like WCC and PageRank because Neptune currently only supports declarative queries. Specifically, Neptune does not support VertexProgram from Gremlin OLAP API.
For Neo4j, JanusGraph, and ArangoDB, we used queries from their built-in algorithm libraries. (We needed to use the Gremlin OLAP API to write WCC for JanusGraph.)
Here are the results:
- Amazon Neptune does not provide native capability to run analytical queries.
- JanusGraph and ArangoDB could not finish WCC or PageRank within 24 hours on the larger graph.
- TigerGraph is about 15x faster than Neo4j for WCC, and 28x to more than 700x faster than the other graph DBs, if they finished.
- TigerGraph is about 2.3x faster than Neo4j for PageRank, and 10x to more than 200x faster than the other graph DBs, if they finished.
Query Speed vs. Cluster Size
We now look at how TigerGraph’s performance scales as the data are distributed across a cluster. In this test, we examine how the increasing the number of compute servers affects query performance. For this test, we used a more economical Amazon EC2 instance type (r4.2xlarge: 8 vCPUs, 61GiB memory, and 200GB attached GP2 SSD). To run on a cluster, we switched from the TigerGraph Developer Edition (v2.1.4) to the equivalent Enterprise Edition (v2.1.6).
We used the Twitter dataset and ran the PageRank query for 10 iterations. We repeated this three times and averaged the query times. We repeated the tests for clusters containing 1, 2, 4, 6, and 8 machines. For each cluster, the twitter graph was partitioned into equally-sized segments across all the machines being used.

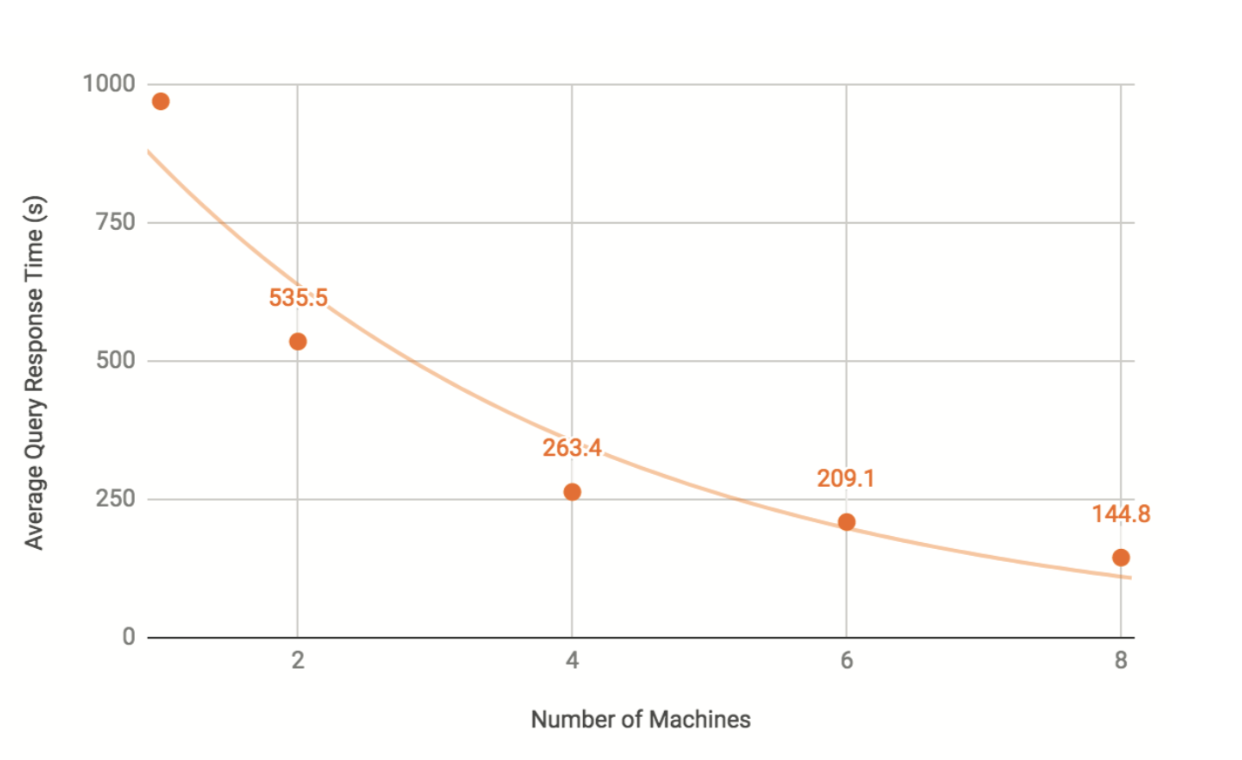
TigerGraph Query Response Time vs. Number Of Machines
We could not perform the scalability test on Neo4j or Amazon Neptune. Neo4j must store the full graph on a single server and cannot partition a graph across multiple machines. Amazon Neptune also cannot partition a graph across multiple machines, nor could we find a way to run PageRank. We have not yet attempted the scalability test on JanusGraph or ArangoDB Enterprise Edition (ArangoDB Community Edition will not perform well when sharded, as noted here https://www.arangodb.com/why-arangodb/arangodb- enterprise/arangodb-enterprise-smart-graphs/).
Reproducibility
All of the files needed to reproduce the benchmark tests (datasets, queries, scripts, input parameters, result files, and general instructions) are available on GitHub: https://github.com/tigergraph/ecosys/tree/benchmark/benchmark/
For machine and system software specifications download the full benchmark at tigergraph.com/benchmark and refer to section 1.
Obviously, we could run additional tests. We’d like to look at pattern matching queries and data update operations. If you have questions or feedback regarding these tests, please contact us at [email protected].
Download the TigerGraph Benchmark for more detailed results:
[maxbutton id=”2″ ]
Download TigerGraph’s Developer Edition:
[maxbutton id=”3″ ]







