





Introduction
Product catalog and inventory management is the foundation and is crucial to the success of any eCommerce or traditional retailer. Selling products through multiple sales channels could easily cause confusion in your business operations without a good management system in place. Keeping an accurate inventory of items in high demand as the business grows is essential for maintaining and improving the customer satisfaction. In times of sudden supply disruption and rapid demand changes due to events such as the COVID-19 Pandemic, retailers have a pressing need to improve the accuracy of their inventory and manage it closely with a rapidly changing item catalog.
Growing Your Business and Responding to Rapid Demand & Supply Changes with Graph
Many pieces of software are capable of managing simple catalogs, but plugging into a graph database opens a whole world of opportunities for your business allowing you to utilize your business data to its fullest potential allowing for a better overall customer experience.
A good catalog management system provides users with a smooth experience when searching for specific products, whether they have the exact name of a product, or only a few attributes or characteristics of a general product. With item catalog powered by TigerGraph, users can quickly narrow down a broad search over the entire catalog. The speed at which product results are returned is unparalleled, as the related products are pre-connected via common attributes or categories, unlike item catalogs built on relational databases, which require complex table joins or item catalogs powered by NoSQL databases, that need scanning the massive key-value pair table multiple times to find related or similar products.
Naturally, people want to see what they want, when they want, as fast as possible. With the power of graph analysis, recommendation systems can be built to potentially show customers what they want before even having to search for it themselves.
The Power of Graph
Putting your catalog data into TigerGraph will allow you to uncover product trends and other analyses unseen in your basic inventory and catalog management tools. These insights can range from finding duplicates in your data to enabling you to market your products based on customer behavior and product conversion rates.
Products don’t always come from one supplier, leading to discrepancies in their descriptions. A good catalog management system allows for standardization of products and descriptions from a variety of suppliers to predefined product categories. A great catalog management system allows for on-the-fly standardization and categorization of products to undefined or new categories such as “curbside pickup eligible”, “pandemic preparedness ”and “COVID-19 Pandemic essentials”.
Normalization of Incoming Data
Utilizing a very common, but powerful graph database use case – entity resolution, we are able to quickly normalize data entries within our catalog graph. For example, any given brand may have nicknames, abbreviations, or even just plain typos when being entered into the database. For example, CK is often used as shorthand for Calvin Klein. When it is entered into the graph, there will be a chance of multiple entities of the same brand. The figure below represents this particular discrepancy in the data. Brands and their respective products loaded into the graph will have the possibility of being “duplicates” of a different name.
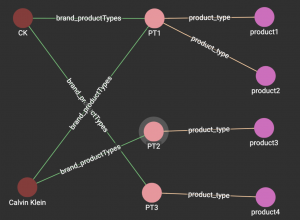
Once all the data is loaded into the graph, we can run an entity resolution query on the graph to do a quick clean up. The resulting subgraph for the Calvin Klein graph will look like the following figure.
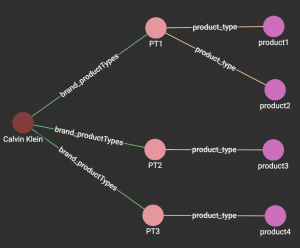
We have chosen to merge the duplicate entities that are determined using the entity resolution query. The products are now all linked to the “Calvin Klein” brand vertex through their respective ProductType vertices.
Analytics on the Fly
Predefined categories consist of such categories as “household”, or “party”. Undefined categories are specific to none, and are defined differently for each situation.
Recently, the impact of COVID-19 has shown us a perfect example of both predefined and undefined categories. With social distancing rules in effect, more people are making use of the curbside pickup option from larger retailers. Different retailers apply their own criteria, allowing curbside pickup for a different predefined range of products. Products from all types of categories are grouped into a “pandemic preparedness” category to market to customers. This would likely include hand sanitizers, Clorox sanitizing wipes, and other types of products that are usually not grouped in the same category. An unlikely, but significantly affected product is toilet paper, which wouldn’t necessarily be part of a COVID-19 kit. With TigerGraph, we are able to create new product categories depending on the current situation of the world around us and add products to it based on the demand changes.
Product Impact Analysis Using TigerGraph
Let’s take a look at how we can use TigerGraph to classify products into undefined categories, and also which products are the most impacted by current product trends.
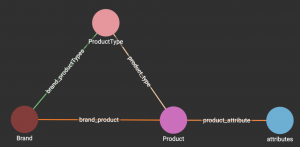
To set up the schema we’ll need 4 vertex types : Product, Brand, ProductType, and Attribute with edges between them. See the graph schema below. This is a simplified schema to illustrate the example.
The example assumes that data normalization is performed before loading the data into TigerGraph. Let’s review the graph analytics of the loaded item data in TigerGraph. Our first query will determine which products are the most impacted by the current product trends. Using the numOfUnits attribute on each product vertex, we can effectively show which products, brands, or types of products that are highest in demand.
In one particular retail catalog use case, we were able to process 230GB of data in around 1 hour. By pre-processing the queries to insert edges (new relationships) and values, we were able to fully connect all of the related items in the graph or connected data within 6 minutes. Previously, that 230GB dataset was loaded into a Hadoop-based NoSQL database and processed with the queries to identify and build the new relationships – it took over 6 hours to identify new relationships, insert and update the values to connect the products with new relationships as opposed to just 6 minutes with TigerGraph.
From this fully connected graph, we were able to run product analysis queries in sub-second times. These queries included finding the top k products or product attributes based on other factors in the graph, the top k similar product types based on an input product, and a brand performance compared to the other brands in the graph. All these queries performed with sub-second response times.
Creating the Undefined Categories
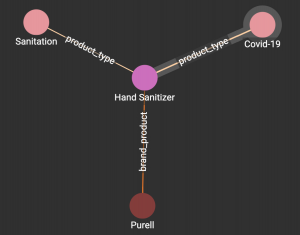
Now that we have our most impacted products, we can create a new productType vertex (category) and add products to this new product category by simply linking existing products to the new productType vertex. The figure below depicts a very simple example of an on-the-fly categorization of a product, creating the new Covid-19 ProducType vertex.
More Than Just a Catalog Management System
Every business needs a catalog management system, so why not get more out of one? We’ve shown that TigerGraph’s capabilities extend beyond simple management of a catalog to also create unique product categories to your own business and provide insights into current and situational trends in the marketplace.
Get Started with TigerGraph Cloud
Register for TigerGraph Cloud at https://www.tigergraph.com/cloud and use the free tier to explore the new starter kit on AWS or Azure Cloud.







