

The world has always been built around connections, but the world today is more hyper-connected than ever before.
Tapping into the power of these rich, growing networks – whether that be financial transactions, social media networks, recommendation engines or global supply chains – will make or break the bottom-line of tomorrow’s leading enterprises.
Given this critical importance of connections in the modern business environment, it’s about time that our database technology kept up.
Legacy databases (known as relational databases or RDBMS) were built for well-mapped, stable and predictable processes like finance and accounting. These databases use rigid rows, columns and tables that don’t require frequent modifications, but when the database model does need to change, it’s an expensive hassle.
But today’s business world is in regular flux – change is the only constant. When building software applications, business and user requirements change all the time. And yet, most legacy database software fights against these changes rather than evolving with them.
Enter graph databases. The graph database model is built to store and retrieve connections from the ground up. It’s more flexible, scalable and agile than RDBMS, and it’s the optimal data model for applications that harness artificial intelligence and machine learning. AI and ML thrive on connected data, and that’s exactly what graph technology delivers.
So, what’s a graph database and what’s it good for? I’m so glad you asked.
What Is a Graph Database?
A graph database stores two kinds of data: entities and the relationships between them.
Data entities are stored as vertices (or sometimes nodes) and data relationships are stored as edges. Vertices represent nouns: people, places, products, locations, payments, and more. Edges represent the verbs or relationships that connect various vertices. This network of interconnected vertices and edges is called a graph.
For example, a customer (vertex) has (edge) an shopping cart (vertex). The edge has connects the customer vertex and the shopping cart vertex.
Here’s another example: An app user (vertex) sends (edge) a payment (vertex) directed to (edge) another app user (vertex). The two app user vertices are connected to the payment vertex via the sends edge and the directed to edge, respectively.
In addition, vertices can have attributes which add more details to each record within a vertex. For instance, a customer vertex might have attributes like name, phone number and credit card number.
Graphs are often best understood visually. The images below are all graphs of vertices and edges that are stored in a graph database.
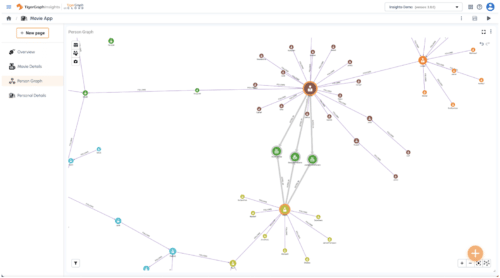
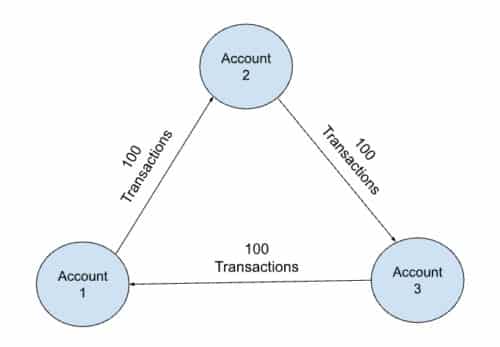
Graph database software stores all the records of these interconnected vertices, attributes, and edges so that they can be harnessed by various software applications. In other words, graph databases store networks of interrelated data.
What Is a Native Graph Database?
As graph technology grows in popularity, more and more database vendors offer “graph” capabilities alongside their existing data models (such as relational, document, wide column, key-value or other NoSQL stores). But the trouble with these graph add-on offerings is that they’re not optimized to store and query the connections between data entities.
If your application frequently needs to store and query data relationships, then you need a native graph database.
The key difference between native and non-native graph technology is what it’s created for. A native graph database – like TigerGraph – uses something called index-free adjacency to physically point between connected vertices in the database. This ensures connected data queries are highly performant.
Essentially, if a database model is specifically engineered to store and query connected data then it’s a native graph database. If the database was first engineered for a different data model and only added “graph” capabilities later, then it’s a non-native graph database.
Non-native graph data storage is often slower because all of the relationships in the graph have to be translated into a different data model (and then back again) for every graph query.
While these differences might not appear critically important, it all comes down to why you’re using a graph database in the first place.
Why Use a Graph Database?
If your application frequently queries and harnesses the relationships between users, products, locations, or any other entities, then you’re better off using a best-in-class native graph database. The same is true if your use case leverages network effects or requires multiple-hop queries across your data.
A graph database is quicker for your development team to modify and quicker for your application to query. Graph database technology also grows and evolves alongside your business and application requirements – it never lags behind or gets stuck in the past.
And it almost goes without saying that if your enterprise relies on graph analytics or graph data science, then you need a native graph database to ensure real-time performance for mission-critical applications.
What Are Graph Databases Used for?
The real question is what are graph databases not used for? The use cases for graph technology are vast, diverse and growing. Here’s a rundown of some of the most popular graph database use cases out there today:
Most Popular Graph Database Use Cases:
Increase Revenue:
Reduce Costs & Manage Risks:
Improve Operational Efficiency:
Foundational Technology:
…and a lot more! Graph technology is a tool to build the future, so there’s no limit to the use cases you might discover.
Who’s Already Using Graph Databases?
Graph databases have been skyrocketing in popularity for more than a decade, and everyone from enterprises organizations to innovative startups is tapping into the power of graph technology.
Here are just some of the leading companies who are already using graph database technology to deliver value to end-users and dominate their industries:
- Intuit: AI-powered knowledge graph
- JPMorgan Chase: fraud detection
- Microsoft Xbox: customer experience
- Ford: entity resolution
- Amgen: social network analysis for healthcare
Of course, these are only a few of the many cutting-edge organizations using graph databases to harness connected data. Discover more graph database users and use cases on the TigerGraph Customers page.
Conclusion
Our world is shaped – and powered – by connections, so it’s time your database software catches up to reality. In fact, graph databases mimic the pattern-matching functions of how the human brain maps the world through neurons (vertices) and synapses (edges). It’s this human-intuitive data model that makes graph technology so unique and powerful.
No matter what your enterprise’s core business, it can be enhanced with the power of connected data. And if your team can tap into the power of data relationships today, you’ll be well ahead of the competition come tomorrow.
If you have any questions, or would like a demo, please contact us at info@www.tigergraph.com.
