






TigerGraph Delivers Latest Large-Scale, Enterprise-Grade Graph Solution to Meet Ever-Growing Customer and Market Demand
TigerGraph today announced its next major product release, TigerGraph 3.2 — a release that includes more than 40 critical enterprise features and positions TigerGraph as the leading large-scale enterprise-grade graph database product in the world. TigerGraph 3.2 includes new availability, scalability, manageability, and security functionalities to ensure mission-critical graph applications work flawlessly in both private and public clouds. This latest enterprise version of TigerGraph will meet ever-increasing demand from the world’s top companies, boost developer adoption and address key data science requirements.
Before we dive into the feature-and-functionality specifics of TigerGraph 3.2, it’s important to note that graph is a major competitive differentiator among the world’s leading companies in virtually every industry — from financial services and healthcare to retail and manufacturing. These organizations need scalable graph technology to answer critical business questions which, in turn, help them understand their customers, reduce fraud risk and optimize their global supply chains. Graph can quickly highlight, discover, and predict complex relationships within data — and the insights gained from graph translate to bottom-line business results.
New 3.2 Enterprise-Grade Capabilities Offer Scale, Simplified Management, Security
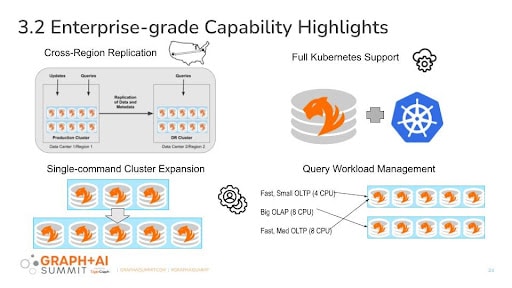
TigerGraph 3.2 includes the following new enterprise-grade capabilities:
- Business continuity support via cross-region replication of TigerGraph clusters
- Demonstrated scale via the 30TB LDBC-SNB BI benchmark; TigerGraph is the first and only commercial vendor to achieve this designation with 70+ billion nodes and 500+ billion edges
- Simplified management via cluster resizing, faster backup and restore, and direct control over resource allocation for big queries
- State-of-art cloud management via built-in Kubernetes support
- Security and access control at scale via user-defined roles

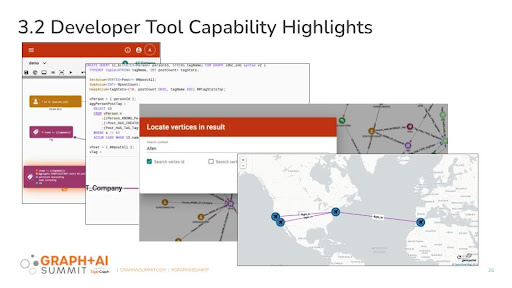
New Features Enhance the Developer Experience
TigerGraph is democratizing the adoption of advanced analytics by making graph accessible and available to more organizations, empowering business users and data scientists to go 10+ levels deep into data, in real-time, across billions of relationships. The new 3.2 release will increase developer adoption with new features that contribute to a more productive developer experience via accessibility compliance, query language enhancement, and query build performance speedup.
These developer-friendly capabilities include:
- WCAG compliant accessibility in GraphStudio
- Enhanced query language features via 30+ more built-in functions, flexible variable definition, flexible query function parameter assignment, flexible query function return, and query function overloading
- Faster and more resilient batch queries for build and install
Data Science Disruption with TigerGraph 3.2
As the leading disruptive innovator in the fast-growing graph database market, TigerGraph continues to push the boundaries of data science. TigerGraph 3.2 caters to data scientists with new advanced machine learning capabilities within the TigerGraph In-Database Graph Data Science Library (formerly Graph Algorithm Library). Data scientists can access double the number of built-in graph algorithms, including new graph embedding algorithms such as Node2Vec and FastRP. The TigerGraph in-database graph data science library has key advantages over other offerings:
- Algorithms run in the database, meaning there is no need to copy the database, and algorithms run on the latest data, not a stale copy
- Database scalability, as TigerGraph is a distributed, scalable database, running as one unit up to tens and hundreds of terabytes
- Massively parallel processing, as algorithms are compute-intensive and parallelizable, so having a graph engine that can take advantage of that potential is a huge advantage to the user
- An all open-source current library using the same GSQL query language and graph engine used for user-authored queries, meaning no challenges with approximation algorithms or partial results and the ability to customize TigerGraph data science algorithms
TigerGraph 3.2 is available now. For detailed release notes, click here.
Still to Come…
TigerGraph is continuing to innovate while working to democratize the adoption of graph technologies for developers, domain experts and business leaders at large. The company will next unveil new, breakthrough GraphQL Data API, Visual Query Builder and Graph Solution Toolkit capabilities and updates.
Stay tuned.







