








So the solution is fewer participants, in more specific and less costly trials. That is, trials must be more targeted. And how can trials be more targeted?
Trials can be more targeted if clinical research teams are able to utilise more of the existing information already available across the world to aid discovery, research and prep – building on what already exists and trialling only the specific gaps in information. Meaning less duplication, less cost and less waste – and much faster results.
If it’s that simple, what’s the problem?
The sheer quantity of information available globally commands very lengthy synthesis processes – where teams of people must spend months, or even years, combing through everything to find, analyse and organise the relevant information from all possible sources. For example, to make use of historical trial data, the team must find studies that meet research criteria, annotate them, and perform statistical analyses to summarise the findings.11 And clinical trial data isn’t the only data source the team must comb through. Other data sources could include for example genomics databases, medical journals, medical databases, patents databases or published competitor data.
Why is all of this information synthesis done manually and not automatically?
In theory, everything can be automated – and this seems like a perfect example. But there are a few things that make automating this synthesis process hard.
First – the information is in different databases, in varying formats and it’s mostly unstructured. That means generally a single computer application can’t meaningfully search through it all at once.
Next – often the relevant information to be extracted is actually found through inference. Clinical research teams can combine learnings from two different sources into a third piece of inferred information that is relevant for the new scenario. Most computer applications can’t infer information very easily – especially not from multiple sources and in multiple formats.
And Then – even when all information has been transformed and combined into a single data store or lake of some sort, often the information has differing levels of confidentiality which must be respected in the access permissions given to users. Balancing the ability to search all of the data holistically with the ability to construct privacy walls throughout the data is a complex technical challenge for most technologies.
And Finally (as if all of that wasn’t complex enough!) – the superset of information that needs to be synthesized for this process is not a static, finished library. There are new trials, new discoveries, new patents, new learnings that are being created and published all the time, all over the world – and all of these must be factored into the process. The ability to constantly add new data into the process can create major automation headaches – especially when the automation rests on some pre-defined or hard-coded rules.
So how does TigerGraph address these challenges and make it possible to automate synthesis?
TigerGraph connects all of your data within its own database and then enables you to use its native and customisable algorithms to search all or any part of that data at once. You could load for example trial data, medical data, patent data, drug or patient data all into the same graph database and then ask any question you need of that connected data. It presents to you the results of your search both as visualised insight and as machine-readable output that can serve as an input to another automated process or visualisation tool.
So what sort of insight could I get from my data using TigerGraph
There are so many different questions you can ask of your connected data that we find it easiest to group them into categories of questions – or in other words types of algorithms. For example, you could identify whether there are specific genes or phenotypes associated with specific symptoms using community detection algorithms, or you could understand how well-cited an article is, and how well-cited its own citations are, using our classification algorithms.
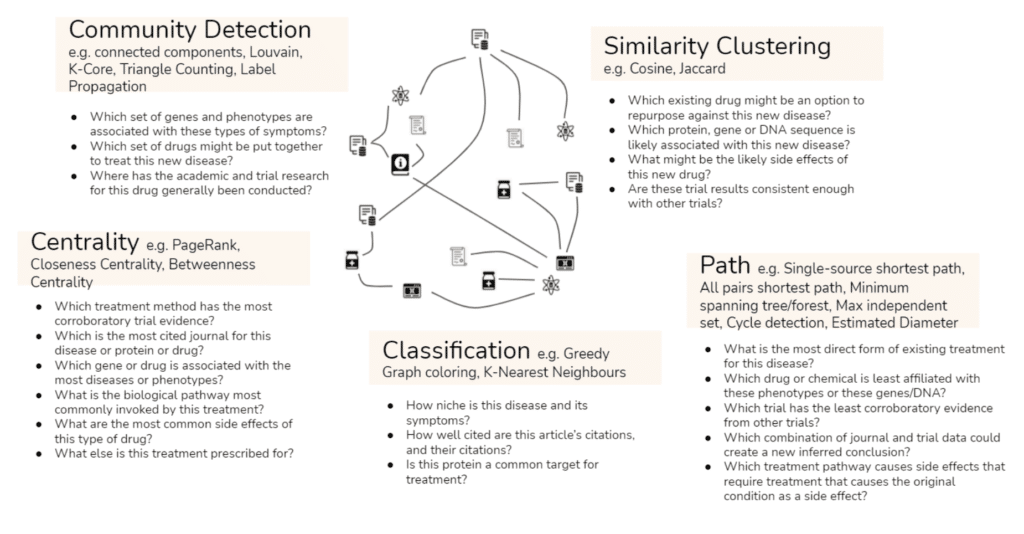
Put simply, with TigerGraph you can automate information synthesis at scale, all in real time. And we know that automated information synthesis is what will drive accelerated drug discovery timelines and enable much more targeted less costly trials.








