

Fraud comes in all shapes and forms across many industries; from account takeovers, to transaction fraud, the financial services industry to healthcare, fraud is both prevalent and costly for many companies. As the world becomes further interconnected and increasingly digital, businesses must adapt to better fight fraudulent activities. In this blog, we will apply graph machine learning techniques to improve fraud detection by up to 20% in the Ethereum blockchain. Follow along with this Jupyter notebook.
Structure of Fraud
Fraudulent activities come in many forms, but a core idea behind fraud detection is to find individuals who behave similar to suspected fraudsters. This might mean using the same address or device id or conducting a similar series of transactions. Given these similarities, and known fraudulent behavior, one can find many fraudsters based on the knowledge of how one operated. The same logic applies to using machine learning for fraud detection. Data scientists need to extract features to feed to their ML pipelines that capture the similarity of various entities that they are trying to classify. In the case of this blog, we are going to be utilizing the structure of Ethereum blockchain transactions to detect account takeover fraud.
Why Graph Machine Learning?
As data scientists try to generate richer features that capture the similarity between different entities, they often look towards graph data structures. Graphs provide a very natural way to represent relationships between entities, such as “Person 1 used Device 36” or “Person 2 transacted with Person 723.” Making a profile of relationships and comparing profiles is the basis for many similarity determinations. If two persons use the same IP address, they will be connected in the graph: Person 1 → IP333 ← Person 2. Additionally, two accounts that transacted with one another would be connected as well. By analyzing these connections and relationships, data scientists can use graph algorithms to extract new features that they wouldn’t have been able to in a traditional tabular setting due to the compute cost of implementing the algorithms through complex JOIN operations. As TigerGraph is a very scalable and performant graph database, leading financial institutions use TigerGraph to compute these novel graph features.
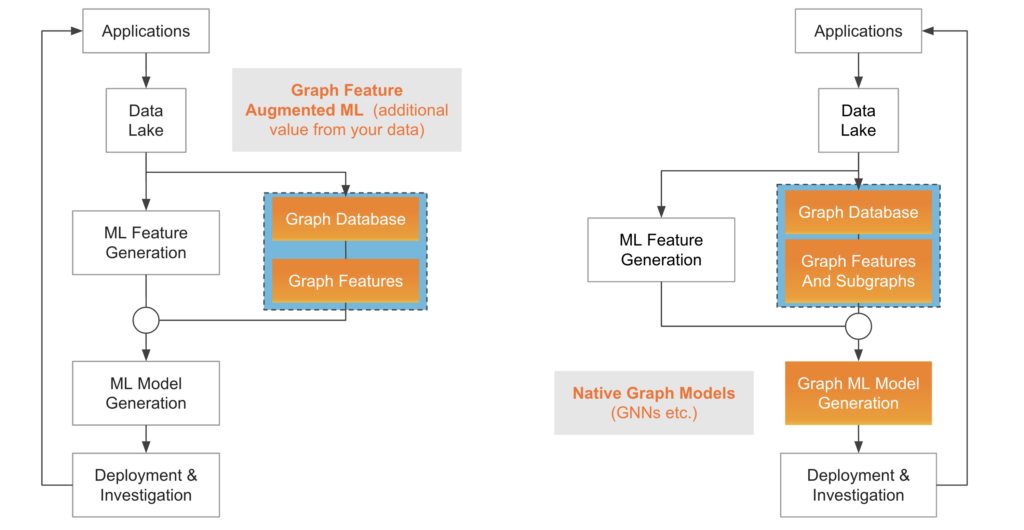
Two methods of Graph Machine Learning. Pictured on the left is incorporating graph features with traditional ML models, while the right represents utilizing native graph ML models such as GNNs.
Graph Machine Learning Applied to Ethereum Fraud Detection
While graph features are a good starting point to detecting more fraud, “native” graph models, such as Graph Neural Networks, incorporate the relationship between data points in a more direct and holistic manner, thereby reducing the need for complex feature engineering pipelines. This gives rise to two different approaches to take when incorporating graph machine learning techniques into data pipelines: one in which graph features are extracted and then passed to traditional, tabular ML models such as XGBoost, or one that uses graph neural networks to make their predictions.
Ethereum Transaction Dataset
The dataset used in the demo comprises transactions on the Ethereum platform, forming a transaction graph for Ether, the second-largest cryptocurrency. Wallets (i.e., accounts) on the platform serve as vertices in the graph, while edges represent transactions between these accounts. With 32,168 vertices and 84,088 edges, the dataset is derived from the publicly available Ethereum dataset from XBlock. We will be predicting if an account is fraudulent or benign.
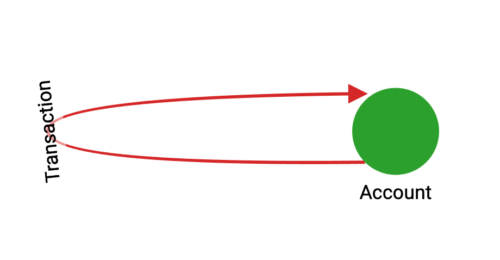
TigerGraph Schema for the Ethereum Dataset
As a baseline test, the notebook trains a model using features that a data scientist might normally calculate in a traditional tabular manner. This includes the amount an account has received, the amount that it has sent, the number of transactions that it has received and sent, and the minimum of the transactions that have been sent and received. Using these features, an XGBoost model achieves a 77% accuracy on the fraud detection task. We will now add more graph-derived features to the model to see how incorporating information from the graph structure of the dataset will improve the accuracy of the fraud detection.

Graph Features And Traditional Machine Learning
The next model in the notebook trains an XGBoost model that incorporates three different graph features: PageRank, Betweenness Centrality, and Weakly Connected Component size. These features are some of the more common algorithms to execute in fraud detection use cases. TigerGraph offers a library of over 50 built-in graph algorithms, organized into seven categories. The notebook’s three features fall into two of those categories described below.
- Centrality: Centrality algorithms, such as PageRank and Betweenness, can measure the influence or closeness of a vertex to others within the graph. Many fraud patterns exhibit higher than average centralities, so these can be useful features for training an ML model.
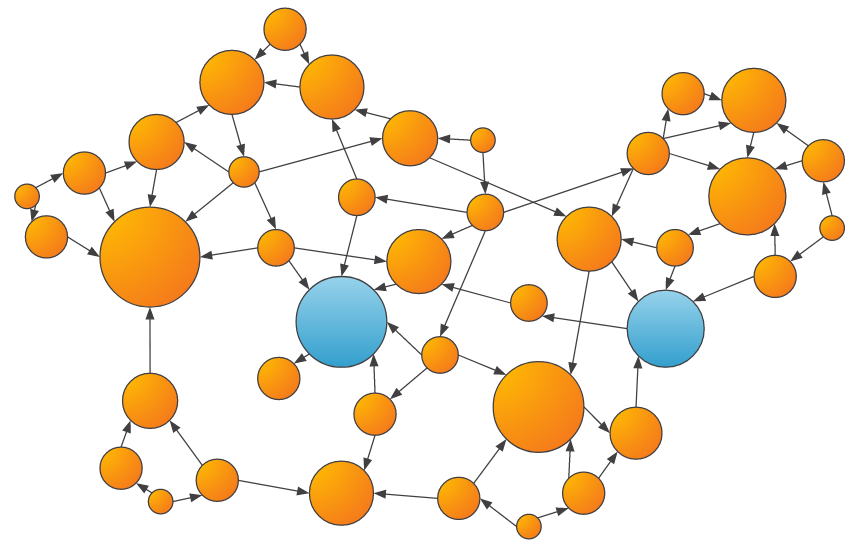
An example of the output of a centrality algorithm, where larger scores are denoted by larger vertices. Entities that are more central have more transaction inflow and outflow, which may be fraudulent behavior.
- Community Detection: Community algorithms, such as Weakly Connected Components (WCC) or Louvain, can be used to determine groups of vertices that share common characteristics or heavily interact with each other. Once the communities are determined, features such as the community size, the number/amount of transactions within the community, and more can be calculated and passed to the ML model.
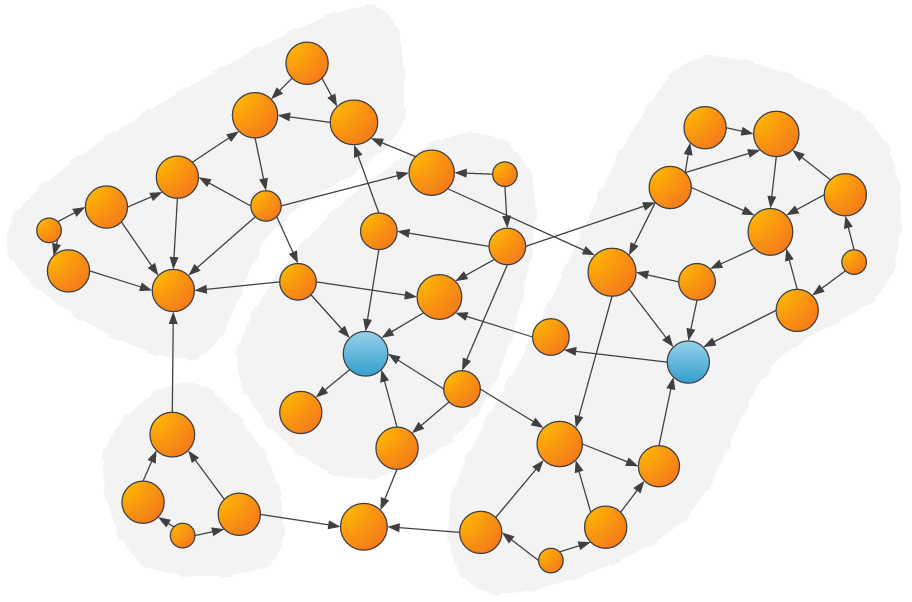
Example of communities detected within a graph. Parties that are within the same community as a suspicious party might be more likely to be suspicious as well.
Another important graph algorithm category is Shortest Path. While not used in this demo, shortest path algorithms can answer questions like “how close is the entity in interest to a known fraudulent entity?”, which may provide a useful signal to the downstream machine learning model.
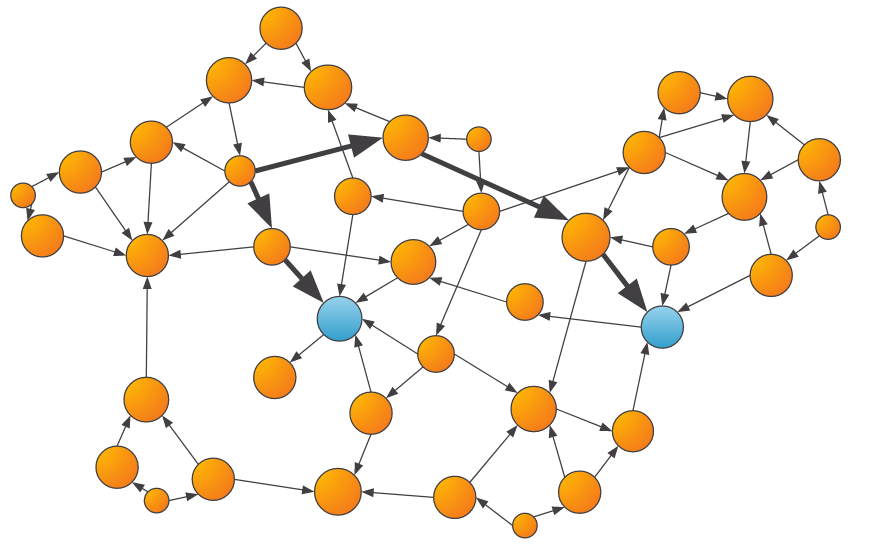
An example of shortest path algorithms determining how close an entity is to a known fraudulent entity.
The different features calculated in the Ethereum dataset resulted in an increase of the XGBoost model accuracy. When used with the traditional features we calculated beforehand, the model achieved a 91% accuracy, a 14% accuracy improvement! In addition, we can view the importance of the features in the model’s decision, and see that PageRank and the size of the Weakly Connected Component are quite important in the model’s classification.
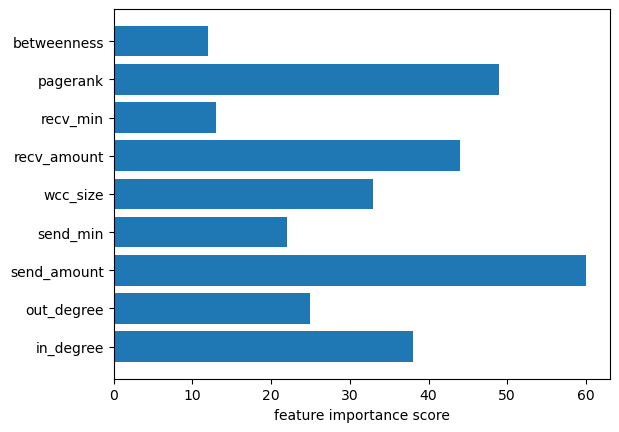
Global feature importance scores from the XGBoost Model trained on graph-derived features.
Graph Embeddings
Graph embeddings are a way to capture a lot of information about the graph in an unsupervised manner, without the need for time-consuming feature engineering that some of the other approaches require. TigerGraph offers graph embedding algorithms in its graph data science library and in its pyTigerGraph Python library. The specific approach that we use here is called FastRP, or Fast Random Projection. The idea behind this algorithm is to perform operations on the graph’s adjacency matrix such that vertices that are highly connected in the graph are close to each other in the embedding space produced.
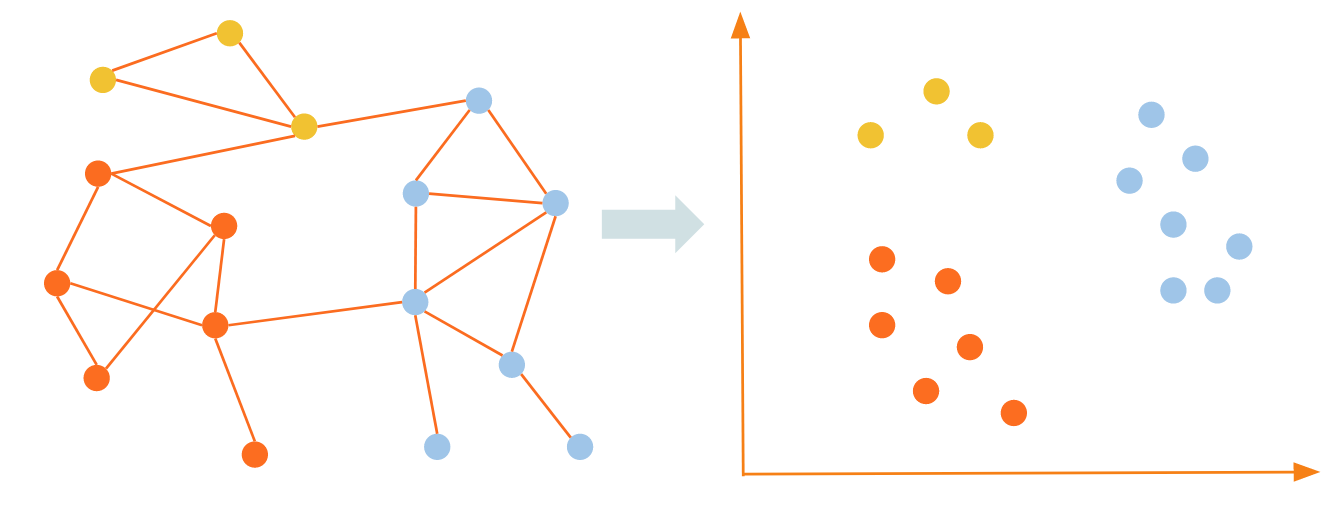
Graph embeddings map vertices that are close together (well connected) in the graph to areas within the embedding space such that they remain close to each other.
Graph embeddings are the best way to incorporate the most amount of graph information into traditional ML algorithms such as XGBoost. However, they do come at a considerable memory and computational cost, so they are not always used. In the Ethereum notebook, we saw they contributed an additional 3% accuracy increase over the model incorporating graph features, for a 17% increase in accuracy over the baseline model. Additionally, as the figure below shows, the holistic nature of an embedding means that it contributes far more to the model than any other single feature.
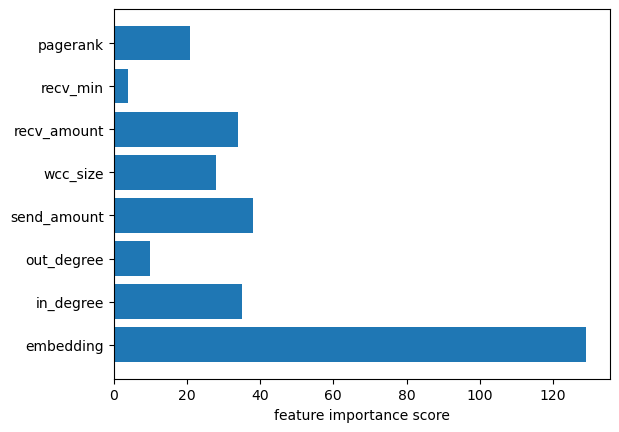
Global feature importance scores from the XGBoost Model trained on graph-derived features and FastRP embedding.
Graph Neural Networks
Graph Neural Networks (GNNs) are a flavor of neural network architecture that operates on graph data structures. These algorithms take into account both the numerical attributes of vertices in the graph, but also the edges between the vertices explicitly. This method can result in an additional accuracy lift over just incorporating graph features into traditional machine learning models. Additionally, they can provide an extra layer of explainability to investigators, as the model not only provides feature importance, but also the importance of the edges between different vertices in the graph.
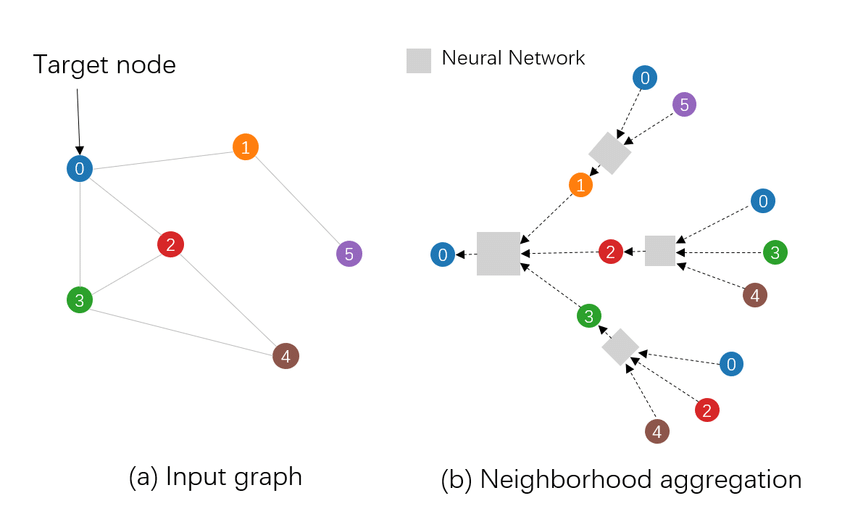
Example of how a Graph Neural Network makes its predictions.
By using the built-in GraphSAGE model in pyTigerGraph, we trained a GNN on the Ethereum dataset. This resulted in an accuracy of 97%, a 20% improvement in accuracy over the baseline model! Additionally, we can view the local feature importance and the subgraph used to analyze why the model made the prediction it did for the exact account we are interested in.
Conclusion
While the example of the Ethereum dataset used throughout the blog focused on one type of fraud and a relatively simple dataset, the ideas presented carry throughout various different industries and types of fraud. By incorporating information about the structure and relationships between data points, graph machine learning techniques provide a substantial accuracy improvement over traditional machine learning techniques. TigerGraph can compute graph-derived features scalably and performantly, leading to more actionable insights and improved outcomes for businesses.
Compilation of results from the Ethereum demo. As more graph structure is incorporated into the ML model, accuracy improves.
A note on TigerGraph
TigerGraph is the leading platform for analytics and machine learning on connected data.
TigerGraph Inc. was established in 2012 and is based in Redwood City, California. TigerGraph is successfully deployed and is adding value to Forbes 2000 customers all over the world. TigerGraph was included in the Gartner Magic Quadrant in 2022, and inducted into the JP Morgan Chase Hall of Innovation in 2021. Forrester Research calculated the average ROI from TigerGraph at over 600% with a payback of less than 6 months.
TigerGraph is the only graph database powerful enough to run graph algorithms at the scale and accuracy required for fraud detection in large enterprises like financial institutions. TigerGraph runs most graph algorithms 10x to 1000x times faster than its nearest competitors, providing more answers, more efficiency, and more time to converge to correct answers. When it comes to scale, there’s no competition. TigerGraph is the only answer for multi-terabyte graphs in a single, non-sharded database.
There are many ways to use TigerGraph – on cloud or on premises. You can sign up for a free instance of TigerGraph Cloud at tgcloud.io or contact us at info@www.tigergraph.com to find out more.
